Humans’ Role in-the-Loop
The research of data integration spans over multiple decades, holds both theoretical and practical appeal, and enjoys a continued interest by researchers and practitioners. Efforts in the area include, among other things, process matching, schema matching, and entity resolution. Matching problems have been historically treated as semi-automated tasks in which correspondences are generated by automatic algorithms and subsequently validated by human expert(s). The reason for that is the inherent assumption that humans “do it better.”
Data integration has been recently challenged by the need to handle large volumes of data, arriving at high velocity from a variety of sources, which demonstrate varying levels of veracity. This challenging setting, often referred to as big data, renders many of the existing techniques, especially those that are human-intensive, obsolete. Big data also produces technological advancements such as Internet of things, cloud computing, and deep learning, and accordingly, provides a new, exciting, and challenging research agenda.
Given the availability of data and the improvement of machine learning techniques, this blog post discusses the respective roles of humans and machines in achieving cognitive tasks in matching, aiming to determine whether traditional roles of humans and machines are subject to change. Such investigation, we believe, will pave a way to better utilize both human and machine resources in new and innovative manners.
We shall discuss two possible modes of change, namely humans out and humans in. Humans out aim at exploring out-of-the-box latent matching reasoning using machine learning algorithms when attempting to overpower human matcher performance. Pursuing out-of-the-box thinking, machine and deep learning can be involved in matching. Humans in explores how to better involve humans in the matching loop by assigning human matchers with a symmetric role to algorithmic matcher in the matching process.
We start by scoping the discussion and introduce the matching problem. Then, we separate the discussion to the role of humans in-the-loop to humans out and humans in.
Matching 101
Modern industrial and business processes require intensive use of large-scale data integration techniques to combine data from multiple heterogeneous data sources into meaningful and valuable information. Such integration is performed on structured and semi-structured datasets from various sources such as SQL and XML schemata, entity-relationship diagrams, ontology descriptions, Web service specifications, interface definitions, process models, and Web forms. Data integration plays a key role in a variety of domains, including data warehouse loading and exchange, data wrangling, data lakes, aligning ontologies for the Semantic Web, Web service composition, and business document format merging ( e.g., orders and invoices in e-commence).

A major challenge in data integration is a matching task, which creates correspondences between model elements, may they be schema attributes (see, for example, Figure 1), ontology concepts, model entities, or process activities. Matching research has been a focus for multiple disciplines including Databases, Artificial Intelligence, Semantic Web, and Data Mining. Most studies have focused on designing high quality matchers, automatic tools for identifying correspondences. Several heuristic attempts were followed by theoretical grounding, showing that matching is inherently an uncertain decision making process due to ambiguity and heterogeneity of structure, semantics, and forms of representation of identical concepts.

We position the matching task as a similarity matrix adjustment process (see Figure 2 for an illustration). A matcher’s output is conceptualized as a (possibly high dimensional) similarity matrix, in which a matcher records the similarity of elements from multiple data sources. Such elements can be attributes in a relational schema, tuples in databases that possibly represent the same real-world entity, etc. A major benefit of this approach is the ability to view schema matching as a machine learning task, paving the way to utilize deep learning models and achieve significant improvements in the ability to correctly match real-world data.
The quality of automatic matching outcome is typically assessed using some evaluation metric (e.g., Precision, Recall, F1). Applying such metrics usually requires human involvement to validate the decisions made by automatic matchers. Yet, human validation of matching requires domain expertise and may be laborious, biased, and diverse. This, in turn, limits the amount of qualitative labels that can be provided for supervised learning, especially when new domains are introduced. Matching predictors have been proposed in the literature as alternative evaluators for matching outcome, opting to correlate well with evaluation metrics created from human judgment.
It becomes clear that while matching tasks have been largely dependent on human validation, human performance in matching and validation does not meet the expectations of those who would like matches with high confidence. For many years there was no other option rather than trusting humans and secretly hoping our experts indeed perform well. The introduction of effective machine learning offers a promise of a better matching world, as will be discussed next.
Humans out
The Humans Out approach seeks matching subtasks, traditionally considered to require cognitive effort, in which humans can be excluded. An initial good place to start is with the basic task of identifying correspondences. We note that many contemporary matching algorithms use heuristics, where each heuristic applies some semantic cue to justify an alignment between elements. For example, string-based matchers use string similarity as a cue for item alignment. We observe that such heuristics, in essence, encode human intuition about matching. Research shows that human matching choices can be reasonably predicted by classifying them into types, where a type corresponds to an existing heuristic. Therefore, we can argue that some of the cognitive effort of human matchers can be replaced by automated solutions. We next briefly describe two examples aiming to enhance the automation of matching using machine learning.
Learning to Rerank Matches: Choosing the best match from a top-𝐾 list of possible matches is basically a cognitive task, usually done by humans. A recent work offers an algorithmic replacement to humans in selecting the best match [1], a task traditionally reserved for human verifiers. The novelty of this work is in the use of similarity matrices as a basis for learning features, creating feature-rich datasets that fit learning and enriches algorithmic matching beyond that of human matching. The suggested ranking framework adopts a learning-to-rank approach, utilizing matching predictors as features. An interesting aspect of this work is a bound on the size of 𝐾, given a desired level of confidence in finding the best match, justified theoretically and validated empirically. This bound is useful for top-𝐾 algorithms and, as psychological literature suggests [2], also applicable when introducing a list of options to humans.
Deep Similarity Matrix Adjustment and Evaluation: Traditionally, the adjustment and evaluation of matching results were done heuristically or by humans. A recent paper shows that these two processes can benefit from deep learning techniques [3]. The work offers a novel post-processing step for schema matching that manipulates, using deep neural networks, similarity matrices, created by state-of-the-art algorithmic matchers (see Figure 3 for example). The suggested methodology provides a data-driven approach for extracting hidden representative features for an automatic schema matching process, removing the requirement for manual feature engineering. Moreover, it enhances the ability to introduce new data sources to existing systems without the need to rely on either domain experts (knowledgeable of the domain but less so on the best matchers to use) or data integration specialists (who lack sufficient domain knowledge).

Humans In
The Humans In approach aims at investigating whether the current role humans take in the matching process is effective (spoiler: it is not) and whether an alternative role can improve overall performance of the matching process (spoiler: it can). A recent study, aided by metacognitive models, analyzes the consistency of human matchers [4]. Three main consistency dimensions were explored as potential cognitive biases, taking into account the time it takes to reach a matching decision, the extent of agreement among human matchers and the assistance of algorithmic matchers. In particular, it was shown that when an algorithmic suggestion is available, humans tend to accept it to be true, in sharp contradiction to the conventional validation role of human matchers.
All these dimensions were found predictive of both confidence and accuracy of human matchers. Specifically, these biases can be used to recognize and capture predictive behaviors in the human decision making process (e.g., decision times and screen scrolls by mouse tracking). A recent research provides a machine learning framework to characterize domain experts that can be used to identify reliable and valuable human experts, those humans whose proposed correspondences can mostly be trusted to be valid [5].
A new matching crowdsourcing application (see Figure 4 for an example screenshot), called Incognitomatch, was launched to support the gathering of behavioral information and offer support in analyzing human matching behavior.
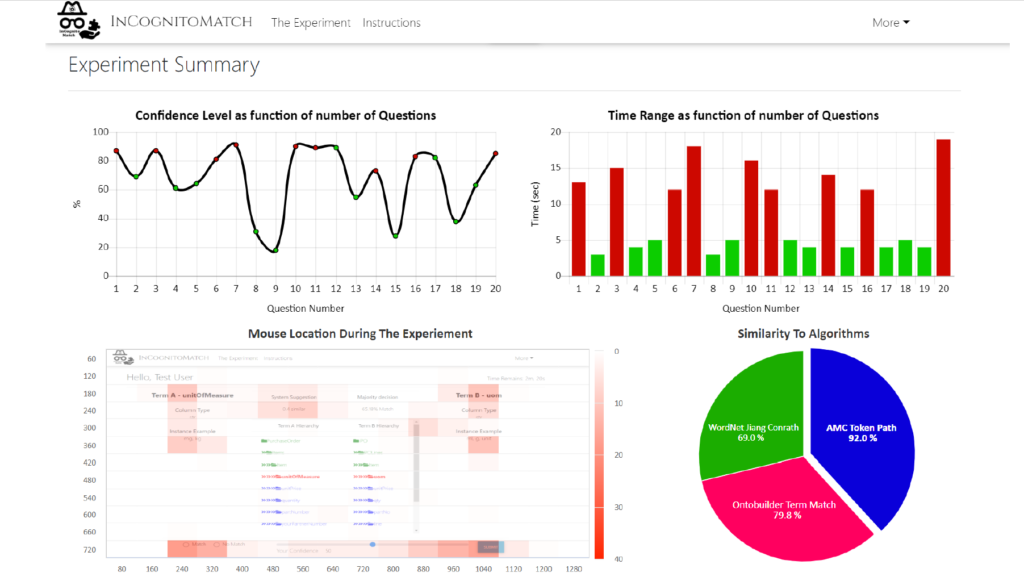
Conslusion
In this blog, we presented our approach for human involvement in the matching loop, introducing tasks where humans can be replaced and emphasizing our vision for understanding human behavior to allow better engagement. An additional overarching goal is to propose a common matching framework that would allow treating matching as a unified problem whether we match schemata attributes, ontology elements, process activities, entity’s tuples, etc.
We envision future research to rely on machine and deep learning to generate new and innovative methods to improve matching problems, making extensive use of similarity matrices. Using machine learning for this purpose immediately raises the issue of shortage of labeled data to offer supervised learning. Hence, pursuing less-than-supervised (e.g., unsupervised, weakly supervised) methods would be a natural next step to pursue.
ACKNOWLEDGMENTS
We would like thank Prof. Rakefet Ackerman, Dr. Haggai Roitman, Dr. Tomer Sagi, Dr. Ofra Amir,and Coral Scharf for their involvement in our research.
References
[1] Gal, A., Roitman, H., & Shraga, R. (2019). Learning to rerank schema matches. IEEE Transactions on Knowledge and Data Engineering.
[2] Schwartz, B. (2004). The paradox of choice: Why more is less. New York: Ecco.
[3] Shraga, R., Gal, A., & Roitman, H. (2020). ADnEV: cross-domain schema matching using deep similarity matrix adjustment and evaluation. Proceedings of the VLDB Endowment, 13(9), 1401-1415.
[4] Ackerman, R., Gal, A., Sagi, T., & Shraga, R. (2019). A cognitive model of human bias in matching. In Pacific Rim International Conference on Artificial Intelligence.
[5] Shraga, R., Amir, O., & Gal, A. (2020). Learning to Characterize Matching Experts. arXiv preprint arXiv:2012.01229 (to also appear in the Proceedings of the International Conference on Data Engineering, ICDE’2021).
Blogger Profiles
Avigdor Gal is a Professor of Data Science at the Technion – Israel Institute of Technology. He is also the Academic Director of Data Science & Engineering for the university’s undergraduate and graduate programs, a member of the management team of the Technion’s Data Science Initiative and the head of the Big Data Integration laboratory in the Technion. In the current age of big data, his research is focused on developing novel models and algorithms for data integration broadly construed, and in particular the investigation of aspects of uncertainty when integrating data from multiple data sources. He is an expert in information systems and data science, and more recently, in machine learning and artificial intelligence.
Roee Shraga is a Postdoctoral fellow at the Technion – Israel Institute of Technology, from which he received a PhD degree in 2020 in the area of Data Science. Roee has published more than a dozen papers in leading journals and conferences on the topics of data integration, human-in-the-loop, machine learning, process mining, and information retrieval. He is also a recipient of several PhD fellowships including the Leonard and Diane Sherman Interdisciplinary Fellowship (2017), the Daniel Excellence Scholarship (2019), and the Miriam and Aaron Gutwirth Memorial Fellowship (2020).
Copyright @ 2020, Avigor Gal, and Roee Shraga. All rights reserved.