Stop publishing so much already!
Got your attention? Now that I have it, I would like to take a few minutes to discuss the role of limited attention and information overload in science. Attentive acts such as reading a scientific paper (or a tweet), answering an email, or watching a video require mental effort, and since the human brain’s capacity for effort is limited (by its oxygen and glucose consumption requirements), so is attention. Even if we could spend all of our time reading papers or answering emails, there is only so much we could read in 24 hours. In reality, we spend far less time attending to things, like science papers, before we get tired, bored, or distracted by other demands of our busy lives.
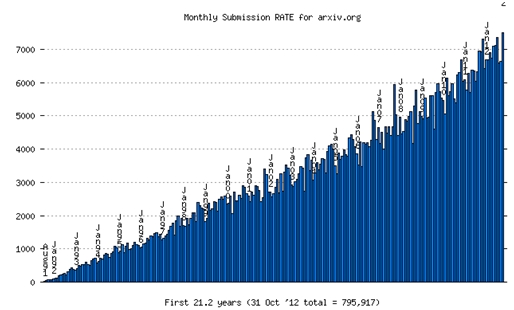
The situation is actually worse. Not only is attention limited, but we must also divide it among a rapidly proliferating number of information sources. Every minute on the Web thousands of new blog posts are written, hours of video are uploaded to YouTube, and hundreds of thousands of status updates are posted on Facebook and Twitter. The number of scientific papers posted to Arxiv.org (see figure) has grown steadily since its inception to more than 7000 a month! Even if you console yourself thinking that only a small fraction of papers is relevant to you, I am willing to bet that the number of papers submitted to the conferences you care about, not to mention the number of conferences and journals themselves, has also grown over the years. What this adds up to is rather nasty case of information overload.
Figure: Monthly submission rate to arxiv.org over more than 21 years. (Source: arxiv.org)
The information overload, coupled with limited attention, reduces the likelihood anyone will notice a specific paper (or another item of information). As a consequence, even real gems will often fail to attract attention, and fade from collective awareness as new items appear on the scene.
Figure: Distribution of time to first citation of papers published by the American Physical Society.

The collective neglect is apparent in the figure above, which reports the time to first citation versus the age of a paper published in the journals of the American Physical Society, a leading venue for publishing physics research. A newly published paper is very quickly forgotten. After a paper is a year old, its chances of getting discovered drop like a rock!
Rising Inequality
One of the puzzles of modern life is that with so much information created daily, people are increasingly consuming more of the same information. Every year, more people watch the same movies, read the same books and cite the same papers than in the previous year. With so many videos available on YouTube, it is a wonder that hundreds of millions have chosen to watch “Gangnam style” video instead.
Figure: Gini coefficient measuring inequality of citations received by APS paper over several decades.

More alarmingly, this trend has only gotten worse. The gap between those who are “rich” in attention and those who are “poor” has grown steadily. One way to measure attention inequality is to look at the distribution of the number of citations. The figure above shows the gini coefficient of the number of citations received by physics papers in different decades. Gini coefficient, a popular measures inequality, is zero when all papers receive the same number of citations, and one paper gets all the citations. Though the gini coefficient of physics citations is already high in 1950s, it manages to grow over the subsequent decades. What this means is that a shrinking fraction of papers is getting all the citations. Yes, the rich (in attention) just keep getting richer.
Figure: Gini coefficient measuring inequality of box office revenues of movies that came out in different years.

Incidentally, inequality is rising not only in science, but also in other domains, presumably for the same reasons. Take, for example, movies. Though the total box office revenues have been rising steadily over the years, this success can be attributed to an ever-shrinking number of huge blockbusters. The figure above shows the gini coefficient of box office revenues of 100 top-grossing movies that came out in different years. Again, inequality is rising, though not nearly as badly in Hollywood as among scientists!
Cognitive Biases
When attention is scarce, the decisions about how to allocate it can have dramatic outcomes. Social scientists have discovered that people do not always rationally weigh alternatives, relying instead on a variety of heuristics, or cognitive shortcuts, to quickly decide between many options. Our study of scientific citations and social media has identified some common heuristics people use to decide which tweets to read or scientific papers to cite. It appears that information that is easy to find receives more attention. People typically read Web pages from the top down; therefore, items appearing at the top of the page have greater visibility. This is the reason why Twitter users are more likely to read and respond to recent messages from friends, which appear near the top of their Twitter stream. Older messages that are buried deep in the stream may never be seen, because users leave Twitter before reaching them.
Visibility also helps science papers receive more citations. A study by Paul Ginsparg, creator of the Arxiv.org repository of science papers, confirmed an earlier observation that articles that are listed at the top of Arxiv’s daily digest receive more citations than articles appearing in lower positions. A paper is also easier to find when other well-read papers cite it. Such indirect exposure increases a paper’s visibility, and the number of new citations it receives. However, being cited by a paper with a long bibliography will not results in many new citations, due to the greater effort required to find a specific item in a longer list. In fact, being cited by a review paper is a kiss of death. Not only is it newer, and scientists prefer to cite more recent papers, but also a review paper typically makes hundreds of references, decreasing the likelihood of discovery for any paper in this long list.
Mitigating Information Overload
No individual can keep pace with the growing deluge of information. The heuristics and mental shortcuts we use to decide what information to pay attention to can have non-trivial consequences on how we create and consume information. The result is not only growing inequality and possible neglect of high quality papers. I believe that information overload can potentially stifle innovation, for example, by creating inefficiencies in the dissemination of knowledge. Already the inability to keep track of relevant work (not only because there is so much more relevant work, but also because we need to read so much more to discover it) can lead researchers to unwittingly duplicate existing results, expending effort that may have been better spent on something else. It has also been noted that the age at which an inventor files his or her first patent has been creeping up, presumably because there is so much more information to digest before creating an innovation. A slowing pace of innovation, both scientific and technological, can threaten our prosperity.
Short of practicing unilateral disarmament by writing fewer papers, what can a conscientious scientist do about information overload? One way that scientists can compensate for information overload is by increasing their cognitive capacity via collaborations. After all, two brains can process twice as much information. A trend towards larger collaborations has been observed in all scientific disciplines (see Wuchty et al. “The Increasing Dominance of Teams in Production of Knowledge”), although coordinating social interactions that come with collaboration can also tax our cognitive abilities.
While I am a technological optimist, I do not see an algorithmic solution to this problem. Although algorithms could monitor people’s behavior to pick out items that receive more attention than expected, there is the danger that algorithmic prediction will become a self-fulfilling prophecy. For example, a paper that is highly ranked by Google Scholar will get lots of attention whether it deserves it or not. In the end, it may be better tools for coordinating social interactions of scientific teams, coupled with algorithms that direct collective attention to efficiently evaluate content, that will provide some relief from information overload. It better be a permanent solution that scales with the continuing growth of information.
> Blogger’s Profile:
Kristina Lerman is a Project Leader at the University of Southern California Information Sciences Institute and holds a joint appointment as a Research Associate Professor in the USC Computer Science Department. After a brief stint as a theoretical roboticist, she found her calling in blending together methods from physics, computer science and social science to address problems in social computing and social media analysis. She writes many papers that are greatly enjoyed by all of their twenty readers.
Copyright @ 2013, Kristina Lerman, All rights reserved.
21 Comments
Comments are closed
You raise a very important concern. It is very easy to be overcome by the amount of information that is available. But our tools to search and locate relevant information are also improving. It is not necessarily clear that the Gini index is increasing simply because the rich get richer, it could be that good papers are just easier to find now then they were in the 50s. How do you control for that?
In particular, I am more optimistic about algorithmic solutions. Not of a centralized ideas like what the top results for Google Scholar (which tends to heavily weigh results by number of citations which reinforces the rich getting richer), but for personalized tools. In particular, the “My Updates” feature of Google Scholar has been very useful for me. It has drawn my attention to new papers in journals I don’t usually read from authors I don’t usually follow. I think there is a lot to be had from machine assistants that know your publication history and interests, and can identify new relevant papers when they come out.
Thank you for your comment Artem. I am a technological optimist too, but for a different reason. I am convinced that new technologies, that I cannot even imagine now, will completely revolutionize how we process information (I want my brain prosthesis now!). People have been worrying about information overload for 2000 years, but we have managed, or mostly. It is like Moore’s law – I am extrapolating the limits of performance based on current technology, but I am sure something will come along that will completely change everything.
I enjoyed reading your post Kristina, my five cents is the analogy with Darwinian evolution. I feel that “too much stuff to read” represent just a (novel) form of evolutionary pressure to which scientists need to collectively adapt. Is unavoidable… as it is any co-evolving pressure in real species evolution. In that sense (yes, almost a religious believe) I am not concerned with the noise of too many publications. While you declare yourself technologically optimist, but unsure of an algorithmic solution, I am confident in evolution…. a better science will spontaneously emerge from such ever evolving landscape.
Dante!! It is good to “see” you (after so many years). Your work on complex behavior in ants had inspired me so much.
Perhaps you are right, and it is certainly fascinating to think of the evolutionary solution (I had not thought of that). For example, the eye evolved the fovea to deal with brain’s inability to process visual information from the retina in real time. How would the pressure of information overload force us to evolve collectively? Who will be the fovea? And who the peripheral vision? Definitely food for thought.
tl;dr 🙂
I think it’s a function of the incremental cost and incremental benefit. 20 years ago, to find papers on my field I had to walk to the library and browse through journal issues and conference proceedings. Before I got to the first interesting paper, I thus had to spent a fair number of minutes, so the incremental cost of reading the paper – or at least its abstract – seemed low. I’d thus get a decent idea of the content and quality of the papers, and each paper was filtered and weighted the same: if it passed peer review, it was there, and there was little or no extra ordering based on number of references, fame of writer etc.
Nowadays it’s so easy to just type keywords into Google, and scan the first 2-3 words of the first 10-20 results. In a matter of seconds we find a paper that’s good enough to tell us what we’re interested in – or worse, to ostensibly back up the unmerited claim we want to make. The extra expense of finding an even better paper on page 73 of the results, with a poorly-chosen title and lesser-known author, just doesn’t seem worth it.
The only thing saving us from convergence to a single paper being the only thing ever referenced is another human flaw: losing track of time while surfing the net. Often, the most interesting things we find are those we weren’t originally looking for at all.
You make good points – while electronic indexing have reduced the cost of search, it efficiency comes at the cost of serendipitous discovery. There is a 2005 Science paper about the narrowing breadth of citation that came with the rise of online publishing.
I am a big believer in the serendipity, and spend hours wasting time on the Web just to increase the chance of a serendipitous discovery!
I know some people that upload papers to arxiv at a given time of the day to get to the top papers in the daily distribution.
You mean, you don’t? 😉
Hi Kristina – great post, and something that resonates with my own experience. On reflection I now tend to outsource more of the keeping-up-with-current-papers to my graduate students than I really should, and I also reference more books than I used to (including ones I read 30 years ago). In a way that’s how the bigger time investment of reading books pays off. By the same token I’m now putting much more writing effort into books than papers.
Hello Alan! It is so nice to “hear” from another person I have not seen in years. I totally agree with you about the need to outsource some of the cognitive effort – my students make me feel much smarter than I am. It is when they leave that I get in trouble. 🙂
So that, rising inequality in everything 🙂
What is the source of your second figure with an actually slow power-law decay? Are there explanations for the exponent 2.3 on the plot?
Sergey – The paper is from our analysis of the APS data set – time to first citation of the paper. No explanation, but I suspect it is due to a multiplicity of ways to discover the paper. Note that time to retweet has an exponent of -1.1 on Twitter (http://arxiv.org/abs/1205.2736), but retweeting is a more homogeneous process.
Really thanks for replying. By the way, the label “no. citations” on the y-axis, is it OK? At first sight, “no. papers” would be more natural. (?) The exponent is bigger than 1… Apparently, there is also a finite fraction of papers that will never be cited, yes? ~ a la condensation at $t=\infty$. It is interesting, how large is this fraction in the APS set?
Good points Sergey. On this chart, there is a 1:1 relationship between citations and papers, so y-axis should be number of papers. I would have to look at a non-loglog version of the plot to see how many papers get no citations at all. Although, I think it is not that many. At the very least, author will cite his previous work. If you excluded author’s self-citations (which we do not have information to do), that number would be much higher.
Really liked your analysis. I’m currently writing a paper…(irony unintended) about how gen-y cope with the 60 second news hour cycle. Your paper very relevant. Thanks
R Tallon
Thank you Rachel.
And so, the problem is clear, but I guess the question is: what do young (unknown but passionate) researchers do about it ? 🙂 (especially ones who try to go interdisciplinary purely because they are really and deeply interested in the scientific problems, with no social, professional, or academic networks that gives them a small “erdos” (or rich) number) 🙂
Ah, that’s a million $$ question. I wish I knew the secret, because I consider myself young (well, maybe not in years, but in your definition as unknown but passionate) researcher myself. Clearly, what’s not going to work is sitting and waiting for the community to discover how great your stuff is. Though I may not make myself popular by saying this, publicity and marketing is very important for scientists. So go ahead and post your papers to arxiv at a specific time (email me for details), write blog posts :), invite yourself to give talks, organize workshops, make friends with other researchers. I even have heard of researchers buying adwords on Google, and showing that it really works in getting citations! At the same time, your work has to be in the mainstream, or no one will cite it. I thought my “theoretical robotics” papers were great, but since no one else is using mathematical models to understand collective behavior of robots, they were not cited. Many more people are interested in social media, and my work in this field is getting far more recognition than robotics work did.
…which is to say that while scientists, designers, and engineers of a previous era had the time to do ONLY science, design, or engineering for most part of the time (not counting teaching which can only sometimes become part of the research), we of this generation, do all of these extra things you mention 🙂 I also guiltily accept that I do almost none of the above:) Does that mean that the ideas on free play and having enough cognitive space left in your brain to think of truly fundamental ideas, will as a consequence, reduce (statistically speaking)? Thanks a lot for your reply, and I will email you 🙂 I have enjoyed having this little chat with you!
Presumably the same applies to comments on a blog. I wonder if (A) Anyone has done a study on that, (B) if I could find it in the vast infosphere, or (C) maybe I should do one myself and publish lots about it.
I’m interested in some of the sources of the data shown, particularly the “time to first citation” graph. Where was that originally published?