ML/AI Systems and Applications: Is the SIGMOD/VLDB Community Losing Relevance?
Overview of DEEM 2018
The ACM SIGMOD Second Workshop on Data Management for End-to-End Machine Learning (DEEM) was successfully held last June in Houston, TX. The goal of DEEM is to bring together researchers and practitioners at the intersection of applied machine learning (ML) and data management/systems research to discuss data management/systems issues in ML systems and applications. This blog post gives an overview of DEEM’18 and a lighthearted summary of the exciting and informative panel discussion.
As per the SIGMOD Workshops chairs, DEEM’18 had 117 registrations–almost half more than the next largest workshop at SIGMOD’18, about thrice as large as a typical SIGMOD/VLDB workshop, and likely the highest in the history of SIGMOD/VLDB workshops! Clearly, this is a red-hot area and our program had stirred the curiosity of a great many people. The day of, about 70-80 people showed up. Thanks to sponsorship from Amazon and Google, we also funded 4 student travel awards. There were 10 accepted papers, with 3 presented as long talks and 7, as short talks. These papers spanned many interesting topics, including new ML programming models, scalable ML on DB/dataflow systems, human-in-the-loop ML exploration tools, data labeling tools, and more. A variety of top schools and some companies were represented. All of this was made possible thanks to the hard work of a top-notch PC. We had 4 excellent invited keynotes/talks from both academia (Jens Dittrich and Joaquin Vanschoren) and industry (Martin Zinkevich from Google and Matei Zaharia with his Databricks hat).
Jens shared his thoughts on what DB folks can bring to ML systems research and education, as well as a recent line of work on using ML to improve RDBMS components. Joaquin spoke about his work on ML reproducibility, collaboration, and provenance management with the successful OpenML effort. Martin gave a unique talk on a topic seldom addressed in any research conference–how to navigate the space of objectives for ML-powered applications before even getting to the data or ML models. He used a very Google-y example of improving user engagement via click measurements. Finally, Matei spoke about the recently announced MLFlow project from Databricks for managing the lifecycle and provenance of ML models and pipelines.
Panel Discussion
Getting to the panel discussion itself, the topic was a hot-button issue: “ML/AI Systems and Applications: Is the SIGMOD/VLDB Community Losing Relevance?” I moderated it and my co-chair, Sebastian Schelter, also helped put together the agenda. To make the discussion entertaining, I played the devil’s advocate and made the questions quite provocative. Apart from the 4 invited speakers, we had 2 additional panelists: Joey Gonzalez (faculty at UC Berkeley) and Manasi Vartak (PhD student at MIT), all of of whom are working on DEEM-style research.

Photos from the workshop. L to R: (1) The DEEM audience. (2) The Panelists: Matei, Joaquin, Jens, Joey, and Manasi (Martin not pictured). (3) Advocatus Diaboli.
First off, I should clarify that the “irrelevance” in our question was meant only in the context of ML systems/applications, not data management in general. After all, as long as there is data to manage, data management research is relevant, right? 🙂 But with the dizzying hype around AI and deep learning, we saw the above question as timely. The panel discussion covered 6 questions. In the rest of this post, I summarize each question, its context/background, and the panel responses and discussion. For brevity sake, I will not always identify who said what.
We started with two fun rapid-fire questions that I often use to put my students on the spot and gauge their technical worldview. What is a “database”? What is a “query”? The Merriam-Webster Dictionary says a database is just an “organized collection” of data, while a query is just a “request for information” against a database. Interestingly, almost all the panelists said similar things although the (wrong) definition that “a database is a system for managing data” did come up once. Most considered a query as a “program” run against a database. No relational. No structured. No system. Not even logic. The panel was off to a flying start!
Q1. Is “in-database ML” dead? Is “ML on dataflow systems” dead? Is the future of ML systems a fragmented mess of “domain-specific” tools for disparate ML tasks?
Context/Background:
There has been almost two decades of work on incorporating ML algorithms into RDBMSs and providing new APIs to support ML along with SQL querying. This avoids the need to copy data and offers other benefits of RDBMSs such as data parallelism. Alas, such in-RDBMS ML support largely failed commercially, according to Surajit Chaudhuri, a pioneer of in-RDBMS ML tools. At XLDB’18, he explained that a major reason was that ML users wanted a lot more tool support (latest models, iterative model selection, complex feature processing) that SAS and similar products offered. Those vendors also recognized the importance of near-data execution and connected their tools to RDBMS servers, leveraging user-defined functionality of such systems to reduce data copying. Moreover, statisticians and data scientists were unfamiliar with SQL and preferred the familiarity of SAS, R, and similar tools, sealing the fate of in-RDBMS ML support at that time. That said, as storage became cheaper, many enterprises no longer mind copying data to Hadoop clusters and using Mahout for ML. Anecdotally, some users also do this to reduce the load on their costly RDBMSs, which they use mainly for OLTP. Spark MLlib and similar “ML on dataflow systems” are now largely replacing Mahout. But in this “era of deep learning,” the programming and execution architectures of both RDBMSs and Spark-style systems seem highly inadequate. So, most users stick to in-memory Python/R for standard ML and TensorFlow/PyTorch for deep learning. Thus, tackling data issues in ML workloads typically requires problem-specific tools. Perhaps ML is just too heterogeneous for a unified system. Hennessy and Patterson recently said that the future of the computer architecture community is in disparate “domain-specific architectures.” Should the DEEM community be content with a similar future for ML systems with no unifying intellectual core like relational algebra/SQL for RDBMSs?
Panel Discussion Summary:
By design, this question induced a sharp polarization among the panel and set the tone for the rest of the discussion. Martin and Manasi agreed that in-database ML is pretty much dead and that custom problem-specific ML+data systems is the inevitable future. Manasi also opined that there will never be an equivalent of SQL for ML in the foreseeable future. Jens countered that even if RDBMSs are dead as an execution engine for ML, relational-style ideas will still be relevant for new custom ML systems, which everyone agreed with. Matei opined that while in-database ML is dying, if not already dead, ML-on-dataflow-systems is alive and well, since he finds many enterprise customers of Databricks adopting Spark MLlib. Joey weighed in based on his experience spanning both ML-on-dataflow and custom ML systems that both kinds of systems will co-exist, albeit with more emphasis on the latter. The overall consensus was that the application space for ML systems is indeed quite fragmented with different operating constraints and environments dictating which tools people will use. Most panelists agreed that while in-database ML may no longer be a particularly promising research direction, ML on dataflow systems, which is a more general environment than RDBMSs, are still a promising avenue for new ideas and will still matter for certain kinds of ML workloads.
Q2. What are the major open research questions for the DEEM community? Is the DB community’s success with RDBMSs a guiding light or just historical baggage?
Context/Background:
Many CS communities are undergoing “crises” and witnessing massive “paradigm shifts,” to borrow Thomas Kuhn’s famous words. Perhaps the best example is the natural language processing (NLP) community. Almost 3 decades of work on feature engineering for applied ML over text have been discarded in favor of new end-to-end deep learning approaches. Some NLP folks say they find the new paradigm refreshing and more productive, while others say they had to take therapy to soothe the trauma caused by this upheaval. In this backdrop, the DEEM community can approach research on ML systems using RDBMSs as a “guiding light” to tackle problems and propose ideas. But this philosophy is fraught with the infamous pitfall of the streetlight effect–only problems/ideas that are easy to connect with RDBMS-style work and/or appease “the RDBMS orthodoxy” will get attention instead of what is truly valuable for ML applications. This pitfall is a highway to practical irrelevance, wherein researchers publish papers that look good to each other, while the “real world” moves on. An alternative philosophy is a clean slate world view in exploring novel problems/ideas in ML systems. But this philosophy is fraught with the risk of repeating history, including wasteful past mistakes in data systems research. Is it even possible to get a judicious mix of both these philosophies?


Panel Discussion Summary:
The first part of the question elicited a wide range of responses. Overall, several major open research problems/topics were identified by the panel, especially the following:
– More support and automation for data preparation and cleaning pipelines in ML
– Abstractions and systems for ML lifecycle and experimentation management
– Efficient ML model serving and better integration of ML models with online applications
– Better visualization support for debugging ML models and data
– Frameworks to think about how to craft ML prediction objectives, especially beyond supervised ML
The second part of the question was met mostly with a measured response that RDBMS ideas will still matter in the context of ML systems but we need to pick and choose depending on the problem at hand. For instance, the DB community has long worked on data preparation, ETL, and data cleaning. But adapting them to ML workloads introduces new twists and requires new research in the ML context, not just routine application or extension of DB work. Joey and Martin also cautioned that it is important to study ML systems problems in the context that matters for ML users and developers, which might often require departing entirely from RDBMS-style ideas. The operating/distributed systems community routinely witnesses such changes. But it is likely that such changes will cause painful “culture shocks” for the DB and DEEM communities, given the stranglehold of the successful legacy of RDBMSs.
Q3. Why has 30yrs of work in the DB community on ETL and data cleaning had almost no impact on data preparation for ML among practitioners?
Context/Background:
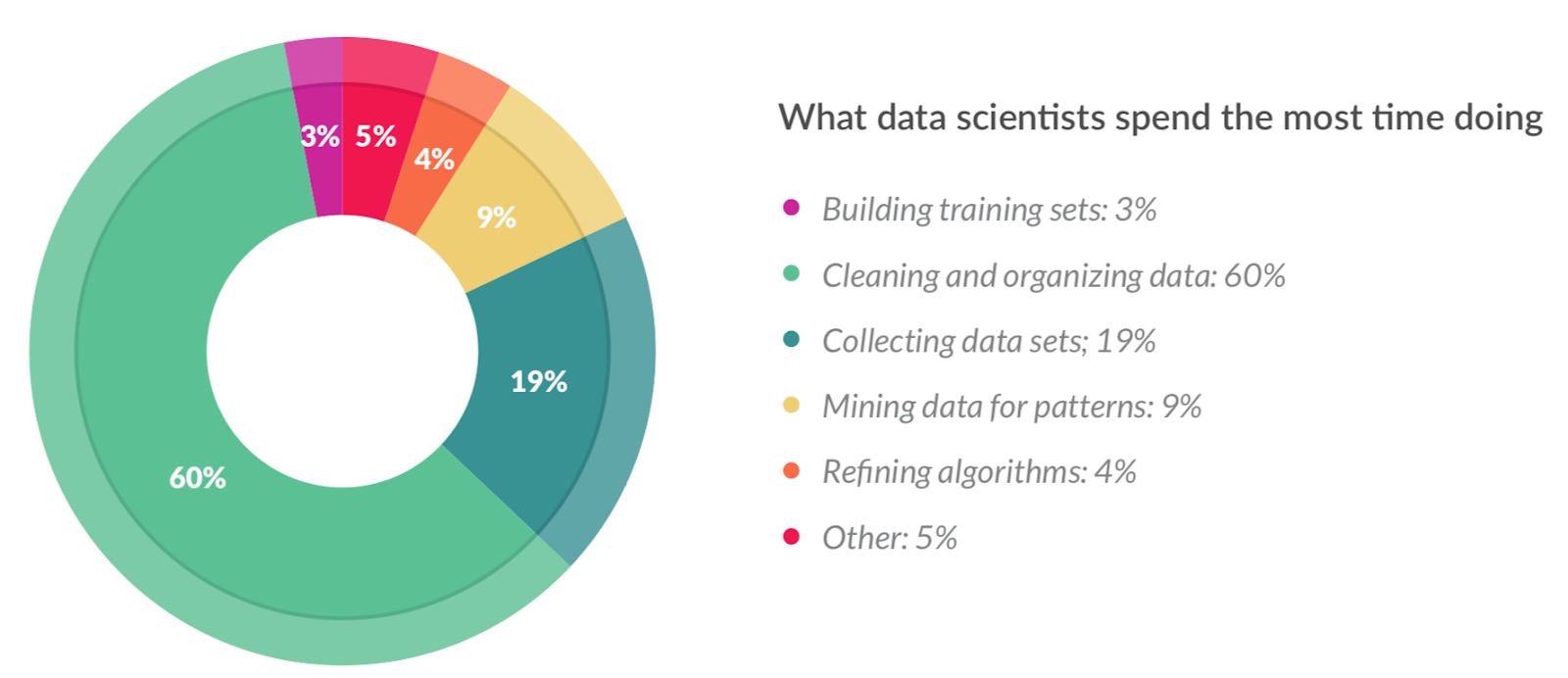
Recent surveys of real-world data scientists, e.g., this massive Kaggle survey and this CrowdFlower report, repeatedly show that collecting, integrating, transforming, cleaning, labeling, and generally organizing training data (often collectively called “data preparation”) dominates their time and effort, up to even 80%. Clearly, this includes data cleaning and integration concerns, which the DB community has long worked on. And yet, none of the data scientists interviewed or anecdotally quizzed seem to have found any techniques or tools from this literature usable/useful for their work. To paraphrase Ihab Ilyas, a leading expert on data cleaning research, “decades of research, tons of papers, but very little success in practical adoption” characterizes this state of affairs. Perhaps data cleaning is just too heterogeneous and too dataset-specific–more like “death by a thousand cuts” rather than a “terrible swift sword.” Perhaps there are just way too many interconnected concerns for a generic unified system to tackle, whether or not it applies ML algorithms internally. What hope is there for DB-style data cleaning work in the ML context when its success in the SQL context is itself so questionable?
Panel Discussion and Summary:
Naturally, the provocative phrasing of the question elicited smiles and raised eyebrows, as well as a heated discussion. I separate the discussion and summary to highlight the different perspectives.
Jens countered that the DB community’s work on data cleaning, especially those that apply ML, have indeed had an impact or at least, look very promising. Joey opined that part of the problem is with the term “cleaning.” A lot of time is inevitably spent by practitioners on understanding and reshaping their data to suit their tools, to bring in domain knowledge, etc., but all such activities get grouped under the catch-all term “cleaning.” Manasi agreed, adding that recasting the data representation for the ML task in peculiar ways also gets talked about as data cleaning or organization. Moreover, almost no ML or data mining curricula teach such data cleaning/prep issues, which skews perceptions. Jens agreed, adding that the “data cleaning” area has a major marketing problem, since it sounds so boring and janitorial. He suggested a clever play on words for naming: “bug data analytics”!
Joaquin said that it will be hard to eliminate humans completely and better human-in-the-loop solutions are needed to reduce manual effort. Jens suggested that pushing more of the cleaning steps into the ML modeling itself could help, similar to what some tree-based models already do. Joaquin agreed that making ML models more robust to data issues is also promising. Joey cautioned that ML will not be a panacea, since it relies on useful signals and enough of it being present in the data to achieve anything useful. One will still need domain expertise to guide the process and set the right objectives. Matei then interjected to opine that the DB community’s work on SQL and dataflow tools has had a major impact on data prep and without this work, the 60% in the survey may very well have been 95% or more! Martin then pondered if an excessive focus on “cleaning” the data is wrongheaded when one should actually be “fixing” the data generating process, especially in Google-like settings, where most of the data is produced by software.
In summary, a major takeaway was that there is likely an unhelpful terminology confusion between researchers and practitioners in the data prep for ML arena, which could hinder progress. Another was to collaborate more with the ML community to make ML models more natively robust to dirty data. But there was consensus that data prep for ML, including cleaning/organizing/transforming data, will remain a core focus for the DEEM community.
Q4+Q5. Is the DB community too obsessed with (semi-)structured data and ignoring the deep learning revolution for unstructured data? On the other hand, is deep learning too overrated for ML analytics outside of “Big Tech” (Google, Amazon, etc.), especially for enterprises?
Context/Background:
These 2 questions are based on 2 key findings from the massive Kaggle survey, shown in the screenshots below.

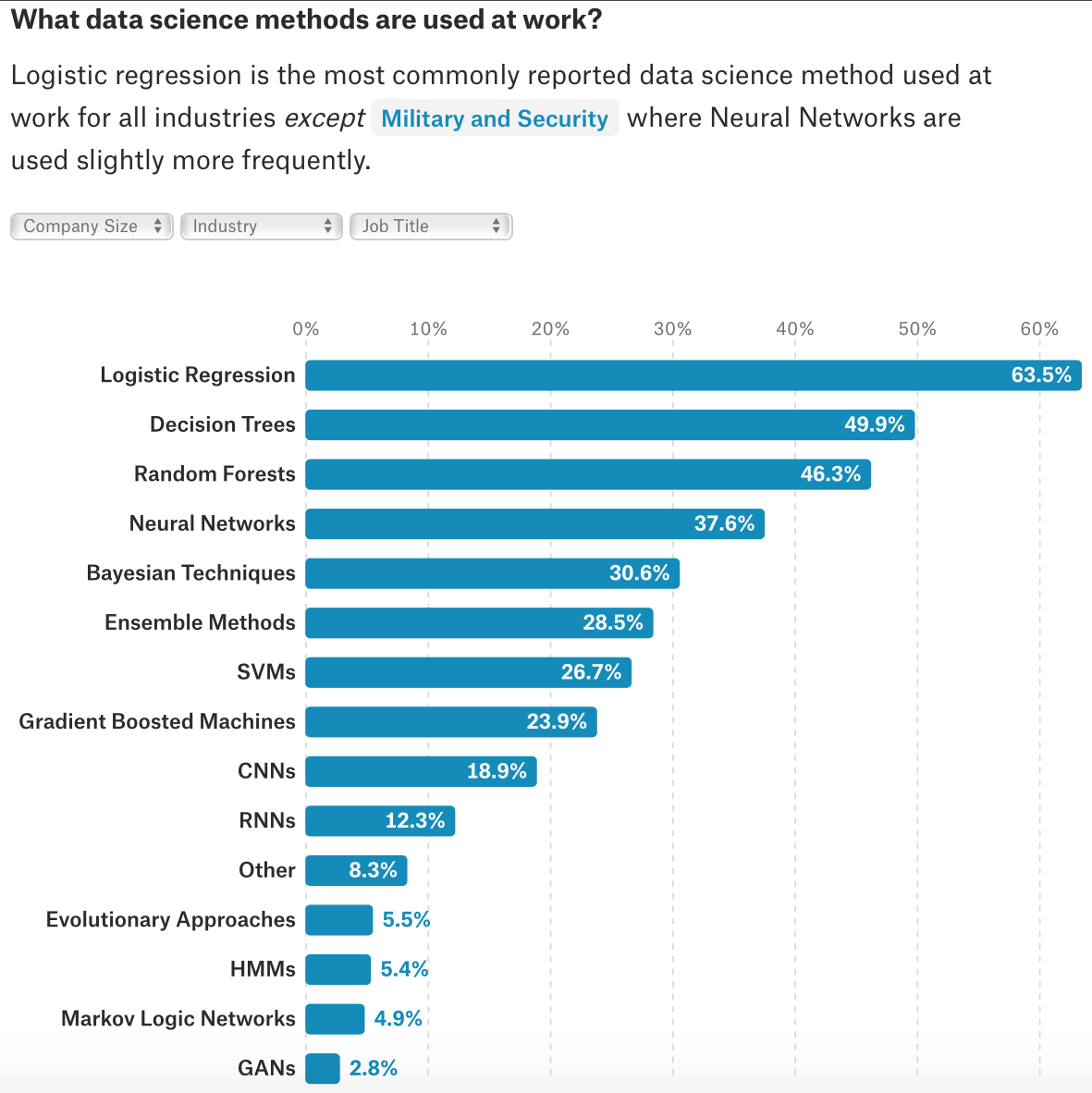
“Relational” data includes both tables and multi-variate time series. Text data is clearly ubiquitous too, while images are not far behind. Given this, should the DB community be thinking more holistically about data rather than shoehorning themselves to structured and semi-structued data? Since deep learning with CNNs and RNNs is the way to go for text and multimedia analytics, the DEEM community should look at deep learning more. But the survey also shows that the most popular models are still linear models, trees, SVMs, Bayes Nets, and ensembles, way above CNNs and RNNs (“neural networks” in this list are likely just classical MLPs). This is likely related to the previous finding — relational data dominates their use cases and interpretability/explainability/actionability are crucial, not just accuracy. GANs, the new darling of the ML world, are at a mere 3%. Overall, there is a huge mismatch in what ML researchers consider “sexy” and what is important for ML practitioners! One might think deep nets are still too new, but the deep learning hype has been around for half a decade before this survey was done. So, one can only conclude that deep learning is overrated for most enterprise ML uses cases. This is a massive rift between the enterprise world and Big Tech/Web companies like Google, Facebook, and Amazon, who are using and aggressively promoting deep learning.
Panel Discussion and Summary:
Once again, due to the amount of interesting discussion these questions generated, I separate the discussion and summary to highlight different perspectives.
Manasi started off by agreeing that deep learning for text, speech, images, and video is something the DEEM community should study more but opined that current deep learning methods do not work on relational data. Thus, there is lots of room for work in this context. Joey bluntly stated that deep learning is indeed overrated and that most real-world ML users will remain happy with linear models, trees, and ensembles (e.g., RandomForest and XGBoost)! He also joked that we should rename logistic regression as a “deep net of depth 1.” The compute cost and labeled data needs of deep nets are impractical for many ML users. Deep nets are also expensive to serve/deploy en masse. While deep nets are useful for speech and images, most users will just download and reuse pre-trained deep nets from Google/Facebook/etc. for such data, not train their own. Overall, his position was that surmising that the whole world will switch everything to deep learning is completely mistaken. For good jovial measure, he then added that his students are all working on deep learning for their papers!
Martin agreed that ML users should start simple but then also try complex models, including deep nets, based on available resources. For images and text, deep nets that exploit their structure are becoming unbeatable. Another key benefit of deep nets is that they are “compact” artifacts. Thus, their serving-time memory access characteristics are better than many other models that need extensive and cumbersome data transformation pipelines for feature engineering. These older models are also a nightmare to port from training to serving. Joey then interjected saying that such serving benefits only hold for “medium-sized” nets, not the 100s of layers ML people go crazy over. Matei weighed in with an anecdote about a Databricks customer. Deep nets are increasingly being adopted for images (and for text to a lesser extent), which are often present along with structured data. One example is “Hotels.com” using CNNs for semantic deduplication of images for displaying on their webpage. But he also agreed that not everyone will train deep nets from scratch. For instance, pre-trained CNNs can be used an image “featurizer” for transfer learning in many cases to greatly reduce both compute and data costs.
In summary, there was a consensus that the DB community should welcome more work on unstructured data and deep learning-based analytics. But there was also caution against getting carried away by the deep learning hype and levity that one should still work on deep learning anyway. The heterogeneity of ML use cases and requirements means that a diverse set of ML models will likely remain popular in practice for the foreseeable future.
Q6. Should the DEEM community break up with SIGMOD and join SysML? What more can we do to enhance the impact of DEEM-style work?
Context/Background:
The DB community’s PC processes, as well as the kinds of research it values are now hotly debated topics. Stonebraker declared recently that SIGMOD/VLDB PCs are unfair to systems-oriented research. While praiseworthy steps are being taken by SIGMOD/VLDB to reduce such DB research culture wars, will this situation lead to DEEM-style work falling through the cracks? SIGMOD/VLDB PC chairs also repeatedly face the issue of not enough ML systems-related expertise/knowledge being available on their PCs and conflation of DEEM-style work with data mining work, worsening the reviewing issues. The SysML Conference was created recently as a home for ML systems research, including DEEM-style work, to avoid such issues. So, in terms of the potential for visibility, research impact, and fairness of research evaluation, is it better for DEEM to break up with SIGMOD and join SysML? What other venues are suitable for DEEM-style work?
Panel Discussion Summary:
This question drew both audible gasps and sniggers from the audience. It was also highly pertinent for at least 2 panelists. Joey helped run the MLSys/AISys workshop at NIPS/ICML and SOSP for the last few years and NIPS BigLearn for a few years before that. Matei helped start SysML in 2018 and is its PC chair for 2019.
Matei readily admitted that as a head of SysML, he will be delighted to have DEEM at SysML. According to him, each paper at SysML will get at least 1 expert reviewer each from ML and systems. The PC meeting will be in person. He opined that SysML is a good fit for DEEM, since DB-inspired work is a core focus of SysML. DB-style ideas can be impactful in the ML systems context as they were with “Big Data” systems. Moreover, since many well-known ML experts are involved with SysML, it offers more visibility among the ML community too. He also suggested that the smaller and more focused communities of NSDI and OSDI are other good options for DEEM-style work that is systems-oriented. SysML will be modeled on their processes. Joey countered that it is perhaps better to keep DEEM at SIGMOD to ensure ML-oriented work gets more visibility/attention in the DB world, which has a lot to offer. He also suggested the MLSys formula of colocating DEEM with 2 different venues, say, in alternate years. One could be SIGMOD and the other could be SysML or an ML venue like NIPS. He wondered if MLSys had overemphasized operating/distributed systems aspects of ML at the cost of other systems-oriented concerns. DEEM at SIGMOD can be a forum for ideas from all DB cultures and can be complementary to SysML.
Martin asked if it was harder to get DB/systems folks to work on ML concerns or vice versa. The latter is widely considered harder. Joey interjected to suggest that building strong artifacts aimed at ML users can improve visibility in the ML world, a la TensorFlow/PyTorch. Martin and Joaquin emphasized the need for solid standardized/benchmark datasets for DEEM-style work on data prep/cleaning/organization/etc. to be taken more seriously in the ML world. This is similar to the UCI repo and ImageNet, both of which boosted ML research. Manasi opined that DEEM-style work need not be so ML-oriented to be publishable at NIPS. But she suggested that SIGMOD/VLDB should create an “ML systems” track/area and add more ML expertise to their PCs. But focusing only on systems-oriented stuff in ML could lead to wasteful repetitions of other DB-style ideas. She said keeping DEEM at SIGMOD will help the DB world stay engaged. Matei had a caveat that without proper ML expertise on PCs, there is a danger of publishing papers that “look nice” but lack ML methodological rigor. While such papers will be discredited in the longer run, they will waste time/resources. Researchers interested in ML systems work should first understand ML well enough. The same holds for PCs. Martin concluded by saying that since a lot of ML systems research studies practical and industrially relevant problems, regardless of the venue, researchers interested in impact should talk to practitioners in industry.
In summary, while the panel was divided on whether DEEM should swap SIGMOD for SysML, they had good suggestions on increasing visibility and impact of DEEM-style work, including building good artifacts, dataset standardization, and bringing more ML experts to SIGMOD/VLDB/DEEM PCs. I closed the discussion declaring that as the DEEM organizers, we have no plans of leaving SIGMOD, since we are thoroughbred “database people,” eliciting laughter from the panelists and the audience, likely in relief. 🙂
Concluding Remarks
Overall, the panel discussion was provocative and passionate but also insightful and constructive. Many of the audience members and panelists later opined that they too found the discussion educational and entertaining. The questions we could not cover included some industry trends and student training issues–another time then. A big thank you again to my fellow DEEM’18 organizers (Sebastian Schelter and Stephan Seufert), the steering committee, the PC, our invited speakers and panelists, the sponsors (Amazon and Google), the officials/volunteers of SIGMOD’18, and all the authors and attendees who made DEEM’18 such a success! I believe DEEM will be back at SIGMOD 2019.
Disclaimer:
We do not own the copyrights for the illustrations used in this article for educational purposes. We acknowledge the sources of the illustrations in order here:
– #1: Thomas Kuhn – The Structure of Scientific Revolutions
– The Drunkard’s Search Effect In Positioning Development And How To Avoid It!
– 2016 Data Science Report by CrowdFlower
– 2017 Kaggle Survey: The State of Data Science & Machine Learning .
If a copyright owner wants their illustration removed, we are happy to oblige.
Blogger Profile
Arun Kumar is an Assistant Professor in the Department of Computer Science and Engineering at the University of California, San Diego. His primary research interests are in data management and data systems for machine learning/artificial intelligence-based data analytics. Systems and ideas based on his research have been released as part of the MADlib open-source library, shipped as part of products from EMC, Oracle, Cloudera, and IBM, and used internally by Facebook, LogicBlox, Microsoft, and other companies. He is a recipient of the ACM SIGMOD 2014 Best Paper Award, the 2016 Graduate Student Research Award for the best dissertation research in UW-Madison CS, and a 2016 Google Faculty Research Award.
Copyright @ 2018, Arun Kumar, All rights reserved.