Automation of Data Prep, ML, and Data Science: New Cure or Snake Oil?
For almost 30 years, the DB / data management community has intensively studied the vexing pains of data integration, cleaning, and transformation. This research has largely been in the contexts of RDBMSs, SQL-oriented business intelligence (BI), and knowledge base construction. But as the emerging interdisciplinary field of Data Science gains prominence, the massive pain of such data “grunt work” in the context of machine learning (ML) and artificial intelligence (AI) applications has taken center stage. Surveys show data scientists spend large amounts of time (e.g., 45%, 60%, or worse!) on such data wrangling and grunt work, often loosely dubbed data preparation (prep). Naturally, reducing the manual burden of data prep is now a major focus for both researchers and companies building ML/AI platforms.
This hot-button panel discussion at SIGMOD 2021 brought together leading experts on these topics from both academia and industry to discuss and debate the past, present, and future of automation of data prep, especially in the context of ML and Data Science. The panelists were Felix Naumann, Ihab Ilyas, Luna Dong, and Sarah Catanzaro. Another panelist, Joe Hellerstein, was unable to join the panel live, but he joined the office hours afterward to share his thoughts. This post explains the background and context for the panel topic and summarizes the actual discussions from my vantage point as the moderator.
Executive Summary
The panel discussed many pressing issues in the context of data prep, including whether automated approaches being pursued by so-called AutoML platforms are indeed realistic, whether the DB community has failed data scientists in this arena, how to objectively compare automated data prep methods, why this area still lacks realistic benchmarks, and how to foster impactful research in this area, including industry-academia collaborations. All questions turned out to be contentious, with no consensus among the panel. But in the end, the lively discussions revealed several new insights on the differing roles of tooling vs. automation, the role of ML itself in automating data prep for ML, gaps between enterprises and Big Tech on operational constraints, and amenability of data prep tasks for benchmarking. All that and also how the DB community often ends up drinking its own kool-aid!
Overview of Panel Discussion
Q1: Is the ML/AI industry selling snake oil on auto data prep? If yes, how so? If not, why do you think not?
Context/Background:
In the last decade, new approaches have emerged for data prep: a human-in-the-loop self-service approach (e.g., Tableau Prep and Trifacta), automation using ML/deep learning models, automation using program synthesis techniques, and various hybrid approaches. But out in the ML/AI marketplace a new breed of “end-to-end” Automated ML (AutoML) platforms are promising the moon with almost no scrutiny or participation from the DB world: the entire workflow from raw data to ML model will be automated, including data prep! Examples include Salesforce Einstein, Alteryx, DataRobot, H2O Driverless AI, and emerging tools from the cloud “whales”, such as Amazon, Google, and Microsoft.
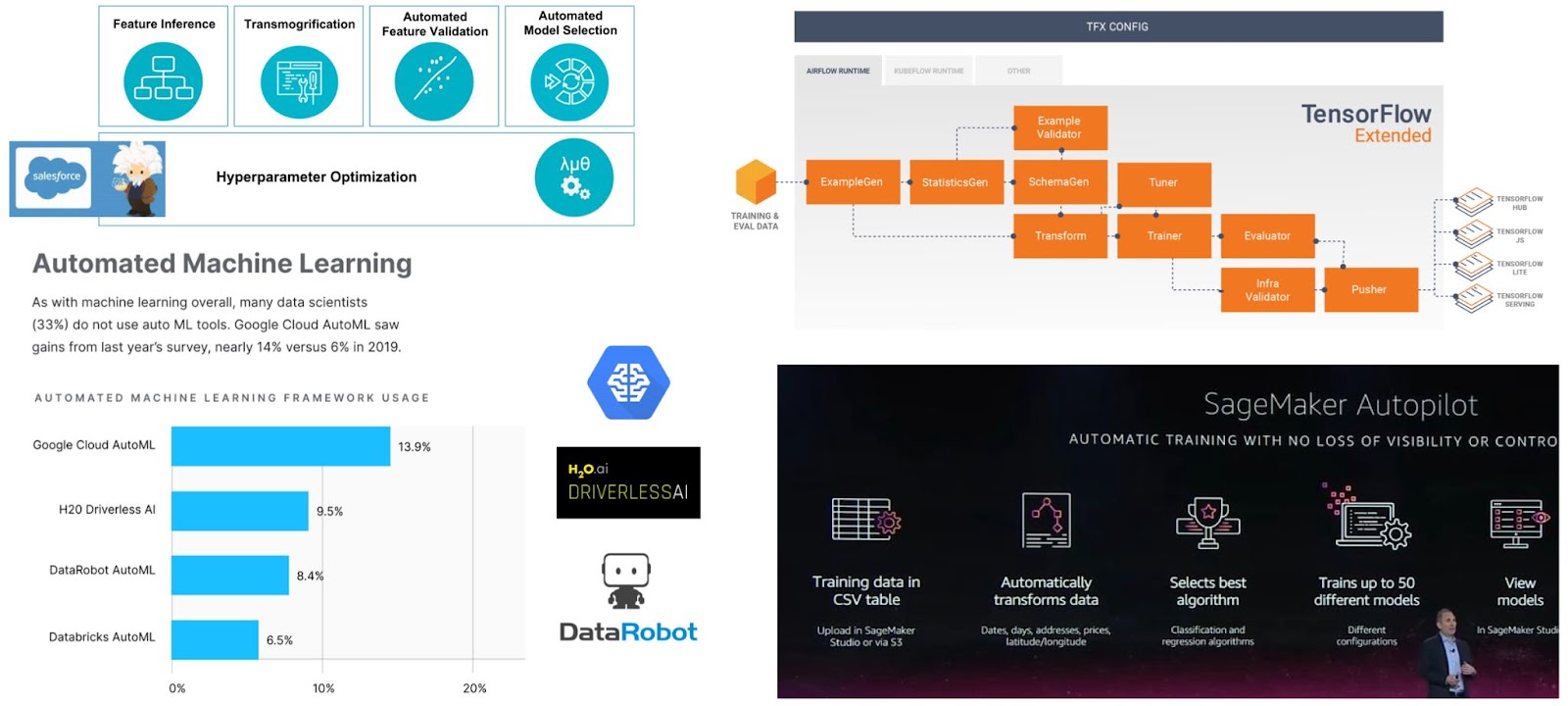
Such platforms are rapidly growing in adoption among enterprises. For instance, Salesforce Einstein alone is apparently used on “hundreds of thousands of datasets” by their enterprise customers. Such companies either cannot afford data scientists (e.g., small city governments) or they use such tools for first-cut proofs of concept. Alas, there is no objective data on how “good” these tools are, especially on data prep. The ML and data mining worlds have studied to death the automation of the ML algorithmics part of the pipeline via so-called “AutoML heuristics” for feature engineering/extraction, hyperparameter tuning, and algorithm/architecture selection. But the implications of how data prep automation and its failures affect end-to-end AutoML pipelines are shockingly ill-understood. This situation has led many researchers and practitioners raising questions over whether customers are being sold effectively “snake oil” by this newly ascendant ML/AI industry (e.g., see this, this, this, and this). Recent research is also highlighting why various steps in end-to-end AutoML are hard to automate.
Panel Discussion Summary:
The panel was naturally polarized on this provocative opening question. Ihab started out by admitting that there is a lot of noise and hype on AutoML but that many new solutions that emerged in the last few years do indeed obviate much grunt work in data prep. He set apart “automation” tools from “self-serve” tools and said both are valuable, walking into a joke about how self-serve tools such as Excel are so much more popular than DB systems. Sarah then bluntly opined that any companies that claim to fully automate data prep are straight up lying! She said there is too much hyperbole in the data prep tools space, as well as the self-serve space. She pondered whether automating data prep is needed at all because it does disservice to deeper understanding of the data and connecting them with business insights. She emphasized a need for building better tools to help data scientists and ML experts understand and prepare data more easily, not automate everything. But I then recollected the Kaggle survey that showed a dramatic rise in adoption of AutoML platforms by some cloud vendors.
Luna weighed in that at Big Tech firms such as Amazon and Google, AutoML is both real and growing in adoption internally. She gave examples of such pipelines at Amazon for Web data extraction and product knowledge graphs that obviate manual work for both data prep and model building. Instead, she said Amazon has many “data associates” who work on annotating and labeling data to be consumed by AutoML pipelines. Data scientists get involved only if prediction failure rates are high. But she added a caveat that all this worked mainly on text data and NLP tasks in domain-specific contexts. She was skeptical that in the near term, it is realistic to expect generic open-domain data prep solutions, especially on tabular data. Sarah interjected to say that often the term “data prep” is used with different meanings and often excludes collection and loading of data, which are also often manual.
Felix then noted that in a past panel discussion people called DB systems as hard to use, especially for loading data. So, he opined that DB systems can also be called “snake oil” in some contexts. But he said “snake oil” is certainly pretty apt for many automated data prep and AutoML tools that obfuscate how the data is transformed. He worried about it becoming a garbage-in-garbage-out situation, except the garbage just smells nice! Ihab expressed surprise at all the skepticism around automation and emphasized that a lot of work has indeed gone into automating many tedious manual data prep tasks. He said such tools go beyond data scientists and also target KBC and general data integration workloads.
Felix clarified that data prep tooling is indeed useful but not necessarily automation. Ihab countered that automated tools do offer high provenance and auditability. He then joked that people do find DB systems easy to use, just not RDBMSs, but rather key-value stores and Kafka. Felix then quipped that it is precisely those kinds of schema-light tools that cause much data prep headaches! Sarah then interjected and shared about a startup in her portfolio that helps data analysts understand and model their schemas better. She emphasized that it is indeed crucial to manage metadata well and that automation of some data prep steps to reduce manual effort is helpful but that full automation is a distraction.
Overall, after a lively and polarized discussion, there was no consensus on this question. Clearly, the heterogeneity of use cases and user types means that some vendors may still get away with selling snake oil and perhaps surprisingly, some users may still find it useful.
Q2: Has the DB community epically failed data scientists in this arena? If yes, why and how to improve? If not, what was impactful?
Context/Background:
The DB community’s tools and techniques, primarily logic-based, have failed to improve the lives of most data scientists. Indeed, Ihab Ilyas himself put the dismal state of affairs in the following terms in a prior talk: “decades of research, tons of papers, but very little success in practical adoption”. However, emerging approaches in the last few years may change the status quo. This includes solutions that use modern ML itself for automating some data prep tasks (e.g., HoloClean), higher-level data validation frameworks such as Deequ, and self-service data prep tools such as Trifacta, which has been making headway in reducing the manual burden of data prep. Are these approaches really promising steps toward more automation? Or will automation that is actually reliable always remain a pipe dream?
Panel Discussion Summary:
Ihab agreed that the DB community was indeed blinded by “ivory tower” phenomena and failed to have much real-world impact in the data prep and cleaning context. But he emphasized that HoloClean does build upon decades of prior work on logic-based approaches, albeit combined with modern ML. He believes reusing constraints and other logic-based methodologies to derive better featurization for ML-based data prep can help build better tools.
Sarah countered that the DB community has not failed data scientists because DB tools have indeed made it far easier for data scientists to work with large and complex datasets. But she worried that the community is indeed failing to place their techniques in the right ML contexts. She gave the example of feature stores, online serving vs. offline analytics, monitoring and understanding data issues in concept drift, and orchestration of data workflows that are very relevant for the ML industry but yet to receive much attention in the DB community.
Luna pondered why ML on tabular data has failed to become as off-the-shelf as NLP, where embeddings and models such as Transformers have succeeded so much to power a new boom in NLP. She noted how NLP used to be harder than ML on tabular data but now the situation has flipped and we are still stuck debating data prep on tabular data. She wondered if a relational tuple can be cast into a meaningful embedding of some sort to make it more amenable to commoditized AutoML pipelines instead of bespoke data prep. Sarah agreed that this could indeed be an exciting and valuable new direction for ML research to help obviate data prep pains. But she noted that lack of access to realistic (dirty) datasets is a major impediment. On that note, we moved on to the last two questions.
Q3+Q4: Are the DB and ML communities full of hot air on benchmarks to evaluate (auto) data prep? How to change this abysmal status quo?
Is DB+ML academic research in this arena just paperware? How to enable academia+industry partnership for actual impact?
Context/Background:
In the immortal words of David Patterson, “benchmarks shape a field … good ones accelerate progress … bad ones help sales.” Both the DB and ML/AI communities have long studied and valued benchmarks: TPC and ImageNet revolutionized the RDBMS and ML worlds, respectively. Benchmarks also exist for the ML algorithmics part of the pipeline (e.g., see OpenML). But curiously, no major benchmarks of renown exist for data prep part of the pipeline. There has been a lot of talk in the DB world on creating such benchmark datasets, e.g., on blogs and at NSF meetings but nothing concrete has manifested yet. Why? What are the roadblocks involved and how to tackle them?

Is the ML/AI industry mainly interested in peddling (questionable) products to boost their profits instead of independently verifiable yardsticks? Are DB and ML researchers/academics mainly interested in peddling (questionable) papers to boost their citation counts and h-indices instead of actually advancing science and technology? Interestingly, both VLDB and NeurIPS recently launched new publication tracks for research on new datasets and benchmarks. The MLPerf benchmark suite also launched “ML Commons” for datasets. Will all this actually help incentivize DB and ML researchers, as well as the ML/AI industry to collaborate on instituting meaningful benchmarks for automated ML data prep?
Panel Discussion Summary:
Felix started out by saying TPC-style benchmarks are “easy” to create because query semantics are precise, whereas data prep is still ill-defined with hundreds of tasks. He called the comparison unfair and said the complexity is partly why data prep benchmarks are lacking. He also said that many data prep tasks are individually easy to perform manually, which means DB researchers probably don’t see them as “hard problems” like, say, relational query optimization.
Ihab quipped that the DB world must beware the “tabloidization” of research caused by chasing benchmarks and leaderboards, e.g., in the NLP world. He opined that the data prep landscape is still too premature for rigorous benchmarks because there is no consensus on task definitions. Thus, he had given up on creating benchmarks in his own work. He suggested a related goal of companies privately sharing real datasets, especially tabular data with all semantics and metadata, is more feasible and worth pursuing. Felix added that he too is pessimistic about generating benchmark data due to the difficulty of capturing myriad rare issues and the element of surprise in data prep.
Sarah then countered both by saying that the same issue of coverage also applies to other benchmark datasets such as ImageNet in vision. But that did not prevent them from spurring a lot of rapid progress in AI. Ihab agreed but added a caveat that unlike vision tasks in data prep are still ill-defined. I then pondered if the panel was making the perfect the enemy of the good. For instance, in my own group’s research on the ML Data Prep Zoo, we did find a few common data prep tasks implemented by multiple end-to-end AutoML platforms; these can indeed be benchmarked on an even footing. Likewise, no one claims that TPC has helped “solve” relational query optimization; but it is still a valuable tool for measurable progress.
That led into the question of how to make data prep benchmarks tractable and how to incentivize such work instead of continuing papers with cherry-picked datasets and little practical impact. Felix said the community can start without a dependency on industry by looking at data prep tasks on open data in myriad domain science applications. Luna said that many AI communities have created benchmark data from Web sources, e.g., scraping the Amazon product catalog. She opined it is not necessary to wait for companies to release large datasets. Sarah then rebutted by saying that while Amazon’s catalog data can be extracted, the hidden data of click logs, user purchase behavior, etc. is the most valuable data for predictive modeling–data that Amazon will likely never release. She said the best “benchmark” is perhaps open sourcing the tools and methods for data prep that allows practitioners to try it out on their own data, see the code, and provide feedback. She suggested DB researchers continue this trend of open sourcing research tools.
Luna opined that “paperware” can still be useful in some cases if practitioners are inspired by methods or techniques that they can adapt and apply to their own setting. She suggested that one of the best ways for academia-industry partnership remains sending students for internships and collaborations to give them exposure to real-world data and tasks. Sarah then added that dynamic and time-evolving tabular datasets are common in industry but receive little attention in academia. She said this could be a valuable area for academia-industry collaboration. I pointed out that academics do not get to customer/user behaviors over time because companies only release snapshots in time, not the whole time series logs. So, releasing more realistic time-evolving datasets could indeed be another good motivation for more industry-academia collaboration and creating more realistic ML data prep benchmarks.
Continued Discussion at Office Hours
Joe Hellerstein joined the other panelists at the office hours to continue the discussion. Three new points arose beyond what the panel discussed: scoping of data prep for different downstream use cases, whether benchmarks are really useful for industry practitioners, and what other forms of impact data prep work can have.
On the first point, Joe opined that data prep as an area is too wide open to be amenable to benchmark-driven progress. It might be more feasible for well-scoped settings such as data prep feeding into some AutoML pipelines but data prep in more general BI contexts, for KBC, etc. are unlikely to be benchmark-amenable. Ihab also noted that data prep outputs are often consumed by humans or Q&A tools such as Alexa; mistakes in such settings are riskier than in AutoML settings. Felix noted that even in a narrower AutoML context, dozens of datasets will be needed for meaningful measurements of data prep’s impact on ML. Luna agreed that a single benchmark dataset like ImageNet will not work for data prep. She said that broader coverage tied to concrete domain-specific cases could help assess data prep’s impact.
On the second point, Sarah noted that enterprises seldom use benchmark results as the main reason for purchasing one product over another, even in the RDBMS and TPC contexts. In the ML tools context, they will likely compare multiple vendors’ products on their internal tasks and data rather than public benchmarks. It is also hard to decouple data prep and downstream ML task goals. Returning to a point Luna made at the panel, she noted that many companies are also resorting to directly embedding raw data to reduce manual data cleaning burden for ML. Ihab noted that this does not solve the data prep issue but just outsources it to ML modeling. I agreed and noted it could overcomplicate the bias-variance-noise tradeoff, since data prep steps in ML affect that tradeoff just like feature engineering or hyper-parameter tuning.
Finally, on the third point, Sarah and Luna surfaced a dichotomy on ML applications of Web companies versus enterprises due to regulations and organizational structures. Web companies can afford to create opaque end-to-end models but many enterprise ML users need more interpretability that is tied to data and attribute semantics. Moreover, data engineering teams in many enterprise companies are often distinct from data science teams and are in charge of complex data transformations. Joe noted that this decoupling means the upstream transformations such as joins already alter the scope of what AutoML tools see and thus raises questions on what benchmarks must target. Ihab noted that ultimately it is still hard for vendors to quantify ROI of data prep tools. Sarah then noted that some of what is called data prep may actually be feature engineering, which is part of what AutoML tools do.
Overall, the panelists noted the need to delineate various classes of consumers of data prep (e.g., BI, AutoML, and KBC) and the need to formalize reference tasks, metrics, and datasets in the ML context. That could be helpful to AutoML platform developers to improve their tools, while still being complementary to the more general landscape of data prep.
Concluding Remarks
Overall, the panel discussion certainly lived up to its hot-button billing, with lively and vigorous debates that were also educational and entertaining. In the end, there was no consensus on whether accurate and reliable automation of data prep on AutoML platforms is a realistic endeavor for the foreseeable future, nor was there a consensus on whether impactful data prep benchmarks with sufficient coverage are feasible in the near term. Even a precise definition of data prep still eludes consensus! But there was indeed a consensus that moving toward more formalized task definitions in data prep specifically in the AutoML context, curating realistic benchmark or reference datasets for some tasks, and fostering more industry-academia collaboration could help reduce the manual burden of data prep for ML and Data Science. Overall, this topic will likely remain fertile ground for both research and development at the intersection of the DB and ML/AI worlds for the foreseeable future.
Bios of Panelists
Felix Naumann. Felix Naumann completed his PhD thesis in the area of data quality at Humboldt University of Berlin in 2000. After a Postdoc period at the IBM Almaden Research Center from 2003 – 2006 he was assistant professor for information integration, again at the Humboldt-University of Berlin. Since 2006 he holds the chair for Information Systems at the Hasso Plattner Institute (HPI) at the University of Potsdam in Germany. His research interests include data profiling, data cleansing, and data integration. More details are at https://hpi.de/naumann/people/felix-naumann.html.
Ihab Ilyas. Ihab Ilyas is a professor in the Cheriton School of Computer Science and the NSERC-Thomson Reuters Research Chair on data quality at the University of Waterloo. His main research focuses on the areas of Data Science and data management , with special interest in data quality, data integration, and machine learning for structured data. Ihab is a co-founder of Tamr, a startup focusing on large-scale data integration, also co-founded inductiv (acquired by Apple), a Waterloo-based startup on using AI for structured data cleaning. He is an ACM Fellow. https://cs.uwaterloo.ca/~ilyas/
Joe Hellerstein. Joe Hellerstein is the Jim Gray Professor of Computer Science at the University of California, Berkeley, whose work focuses on data-centric systems and the way they drive computing. He is involved in a number of commercial ventures, notably in this context as co-founder and Chief Strategy Officer of Trifacta, the Data Engineering Cloud vendor that also powers Google Dataprep.
Luna Dong. Xin Luna Dong is the Head Scientist at Facebook AR/VR Assistant. Prior to joining Facebook, she was a Senior Principal Scientist at Amazon, leading the efforts of constructing Amazon Product Knowledge Graph, and before that one of the major contributors to the Google Knowledge Vault project, and has led the Knowledge-based Trust project, which is called the “Google Truth Machine” by Washington’s Post. She has co-authored books “Machine Knowledge: Creation and Curation of Comprehensive Knowledge Bases” and “Big Data Integration”.
Sarah Catanzaro: Sarah Catanzaro is a Partner at Amplify Partners, where she focuses on investing in and advising high potential startups in machine intelligence, data management, and distributed systems. Her investments at Amplify include startups like OctoML, RunwayML, Hex, and Meroxa among others. Sarah also has several years of experience defining data strategy and leading data science teams at startups and in the defense/intelligence sector including through roles at Mattermark, Palantir, Cyveillance, and the Center for Advanced Defense Studies.
Blogger Profile
Arun Kumar is an Associate Professor in the Department of Computer Science and Engineering and the Halicioglu Data Science Institute and an HDSI Faculty Fellow at the University of California, San Diego. His primary research interests are in data management and systems for machine learning/artificial intelligence-based data analytics. Along with his PhD advisee, Vraj Shah, and other students, his recent work on the ML Data Prep Zoo is creating new labeled datasets and benchmarks for data prep automation on AutoML platforms. He has given invited talks on that effort to Google, Microsoft, and Amazon. Google is exploring adoption of models from that work into the TensorFlow Extended platform. Amazon and OpenML have also expressed similar interest. He served as an inaugural Associate Editor for VLDB’s Scalable Data Science Research category in 2020-21, helping shape its rationale and criteria.
Copyright @ 2021, Arun Kumar, All rights reserved.