Time Series Anomaly Detection
What it is, how it works, where we are, and where we are heading
Anomaly detection is an important problem in data analytics with applications in many domains. In recent years, there has been an increasing interest in anomaly detection tasks applied to time series. In this post, we take a holistic view on anomaly detection in time series, starting from the core definitions and taxonomies related to time series and anomaly types, to a brief description of the anomaly detection methods proposed by different communities in the literature. We conclude with the recent benchmark and evaluation effort proposed recently in the data management community, and new perspectives and research direction.
Time Series
A wide range of cost-effective sensing, networking, storage, and processing solutions enable the collection of enormous amounts of measurements over time. Recording these measurements results in an ordered sequence of real-valued data points commonly referred to as time series (see Figure 1). More generic terms, such as data series or data sequences, have also been used to refer to cases where the ordering of data relies on a dimension other than time (e.g., the angle in data from astronomy, the mass in data from spectrometry, or the position in data from biology [1]. The analysis of time series has become increasingly prevalent for understanding a multitude of natural or human-made processes. Unfortunately, inherent complexities in the data generation of these processes, combined with imperfections in the measurement systems, as well as interactions with malicious actors, often result in abnormal phenomena. Such abnormal events appear subsequently in the collected data as anomalies. Considering that the volume of the produced time series will continue to rise due to the explosion of Internet-of-Things (IoT) applications, an abundance of anomalies is expected in time series collections.
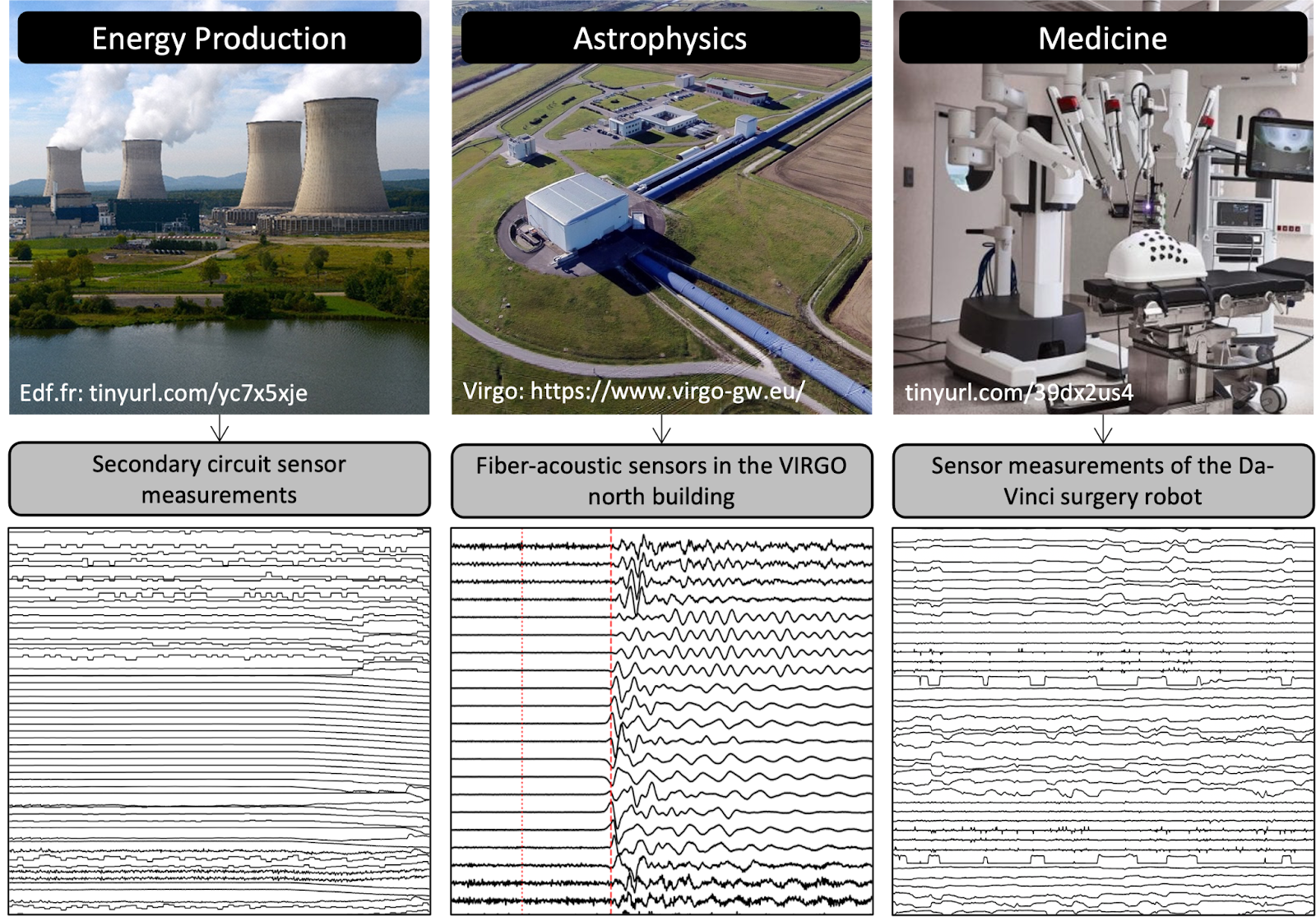
Figure 1: Example of domains and applications
On the Definition of Anomalies in Time Series
Attesting to the challenging nature of the problem at hand, we observe that there does not exist a single, universal, precise definition of anomalies or outliers. Traditionally, anomalies are observations that deviate considerably from the majority of other samples in a distribution. The anomalous points raise suspicions that a mechanism different from those of the other data generated the specific observation. Such a mechanism usually represents either an erroneous data measurement procedure, or an unusual event; both these cases are interesting to the analysts.
Subsequence versus Points: a Core Difference
There is a further complication in time-series anomaly detection. Due to the temporality of the data, anomalies can occur in the form of a single value or collectively in the form of subsequences. In the specific context of point, we are interested in finding points that are far from the usual distribution of values that correspond to healthy states. In the specific context of sequences, we are interested in identifying anomalous subsequences, which are usually not outliers but exhibit rare and, hence, anomalous patterns. In real-world applications, such a distinction between points and subsequences becomes crucial because even though individual
points might seem normal against their neighboring points, the shape generated by the sequence of these points may be anomalous.
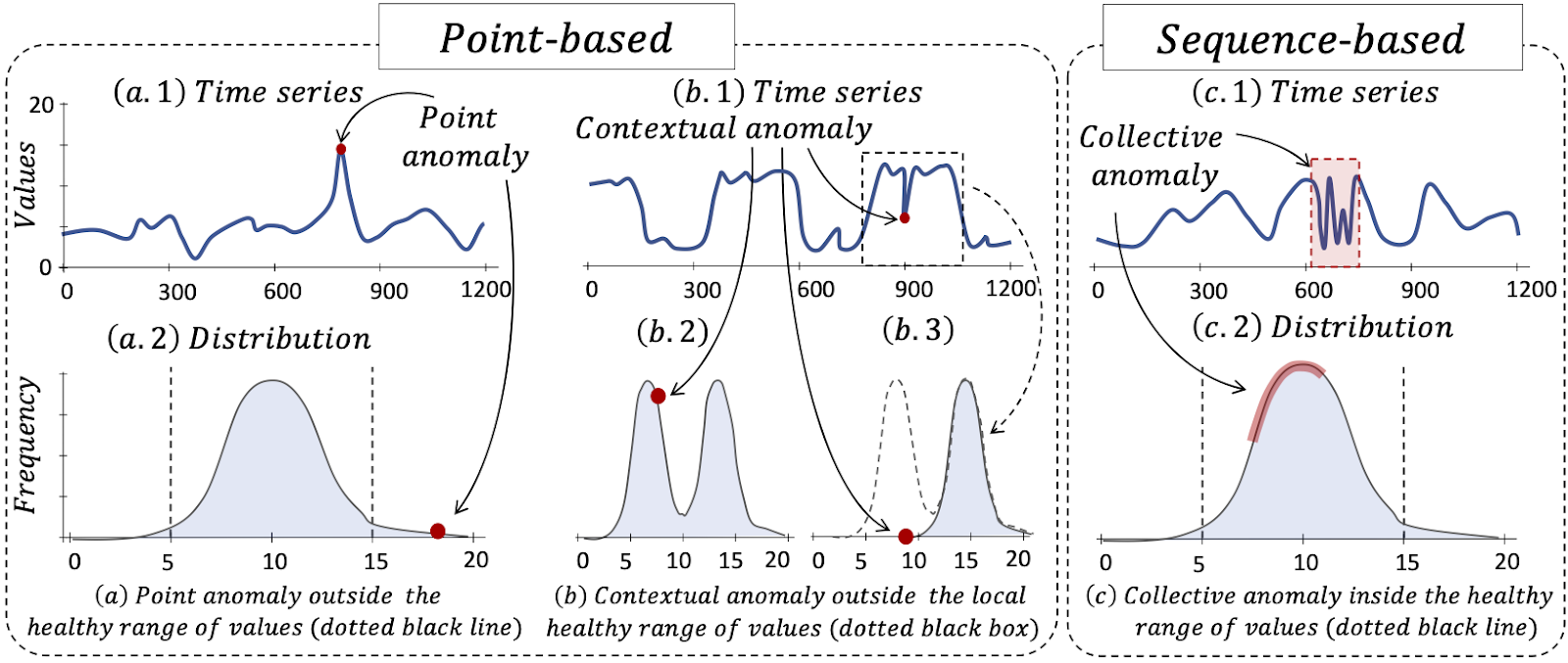
Figure 2: Point-based versus sequence-based anomalies
Formally, we define three types of time series anomalies: point, contextual, and collective anomalies. Point anomalies refer to data points that deviate remarkably from the rest of the data. Figure 2(a) depicts a synthetic time series with a point anomaly: the value of the anomaly is outside the expected range of normal values. Contextual anomalies refer to data points within the expected range of the distribution (in contrast to point anomalies) but deviate from the expected data distribution, given a specific context (e.g., a window). Figure 2(b) illustrates a time series with a contextual anomaly: the anomaly is within the usual range of values (left distribution plot of Figure 2(b)) but outside the normal range of values for a local window (right distribution plot of Figure 2(b)). Collective anomalies refer to sequences of points that do not repeat a typical (previously observed) pattern. Figure 2(c) depicts a synthetic collective anomaly. The first two categories, namely, point and contextual anomalies, are referred to as point-based anomalies. whereas, collective anomalies are referred to as sequence-based anomalies.
As an additional note, there is another case of subsequence anomaly detection referred to as whole-sequence detection, relative to the point detection. In this case, the period of the subsequence is that of the entire time series, and the entire time series is evaluated for anomaly detection as a whole. This is typically the case in the sensor cleaning environment where researchers are interested in finding an abnormal sensor among all the functioning sensors.
What about Multivariate Anomalies?
Another characteristic of time-series anomalies comes from the dimensionality of the data. Univariate time series consists of an ordered sequence of real values on a single dimension, and the anomalies are detected based on one single dimension (or feature). In this case, as illustrated in Figure 3(b.1), a subsequence can be represented as a vector.
On the other hand, Multivariate time series is either a set of ordered sequences of real values (with each ordered sequence having the same length) or an ordered sequence of vectors composed of real values. In this specific case, as illustrated in Figure 3(b.2), a subsequence is a matrix in which each line corresponds to a subsequence of one single dimension. Instances of anomalies are detected according to multiple features, where values of one feature, when singled out, may look normal despite the abnormality of the sequence as a whole.
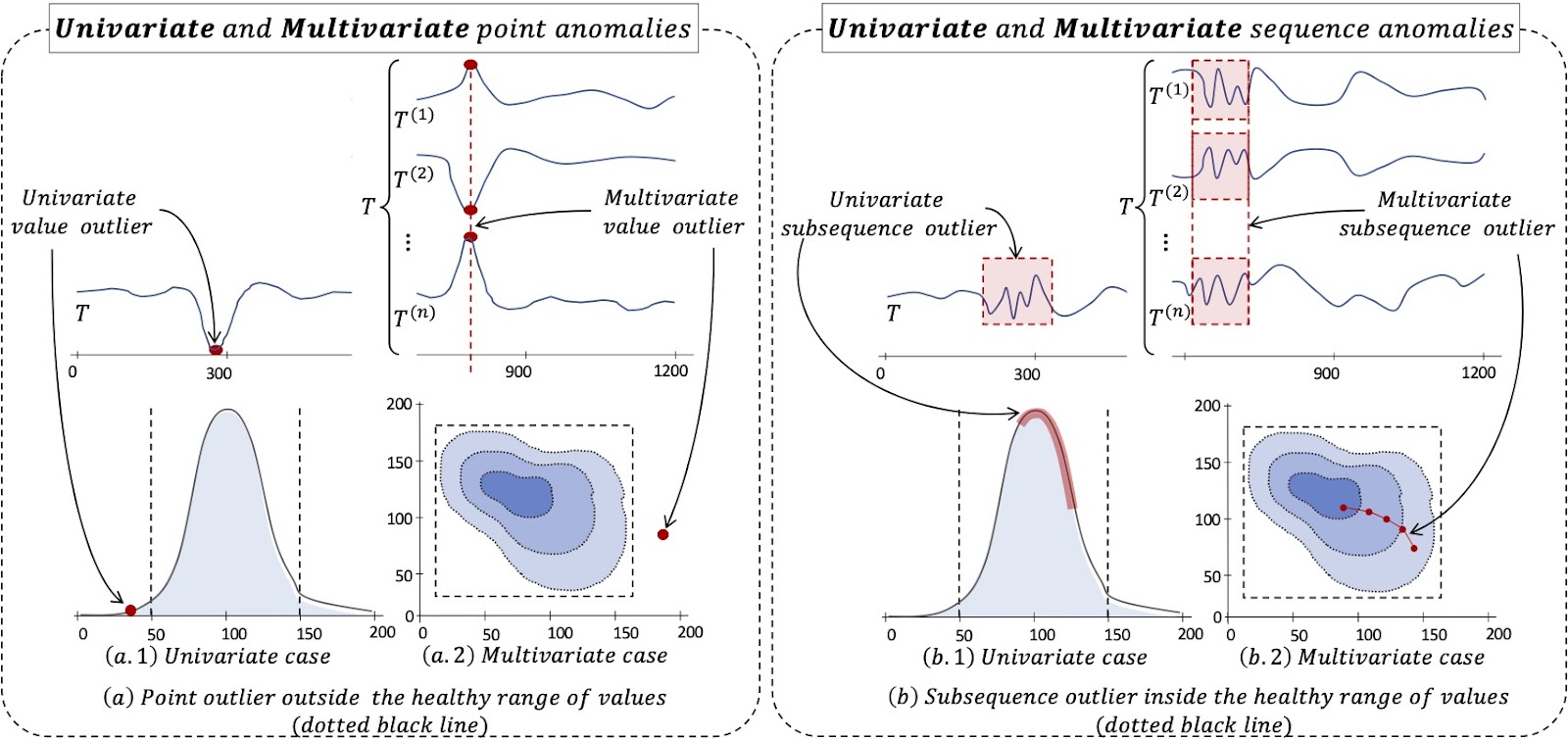
Figure 3: Univariate versus multivariate anomalies
As an additional note, the rise (but not domination) of deep learning methods for multivariate time series anomaly detection can be explained by the fact that multivariate subsequences (i.e., matrices) are natively handled by deep neural networks (composed of filters of a given length sliding over multiple channels).
Human Knowledge in the Loop (or not)
The anomaly detection task can be divided into three distinct cases: (i) experts do not have information on what anomalies to detect, and do not know how to characterize normal behavior either; (ii) experts only have information on the expected normal behavior; (iii) experts have examples of anomalies they have to detect (and have a collection of known anomalies). This gives rise to the distinction among unsupervised, semi-supervised, and supervised methods.
Unsupervised: In case (i), one can decide to adopt a fully unsupervised method. These methods have the benefit of working without the need for a large collection of known anomalies and can detect unknown abnormal behavior automatically. Such methods can be used either to monitor the health state or to mine the historical time series of a system (to build a collection of abnormal behaviors that can then be used on a supervised framework).
Semi-supervised: In case (ii), methods can learn to detect anomalies based on annotated examples of normal sequences provided by the experts. This is the classical case for most of the anomaly detection methods in the literature. One should note that this category is often defined as Unsupervised. However, we consider it unfair to group such methods with the category mentioned above, knowing that they require much more prior knowledge than the previous one.
Supervised: While in case (i) and (ii) anomalies were considered unknown, in case (iii), we consider that the experts know precisely, what type of pattern(s) they want to detect, and that a collection of time series with labeled anomalies is available. In that case, we have a database of anomalies at our disposal. In a supervised setting, one may be interested in predicting the abnormal subsequence by its prior subsequences. Such subsequences can be called precursors of anomalies.
Detecting Anomalies in Time Series: a Generic Pipeline
The various different algorithms proposed for anomaly detection in time series usually follow the same pipeline. This pipeline consists of four parts: data pre-processing, detection method, scoring, and post-processing. Figure 4 illustrates the process. The decomposition of the general anomaly detection process into small steps of a pipeline is beneficial for comparing different algorithms on various dimensions.
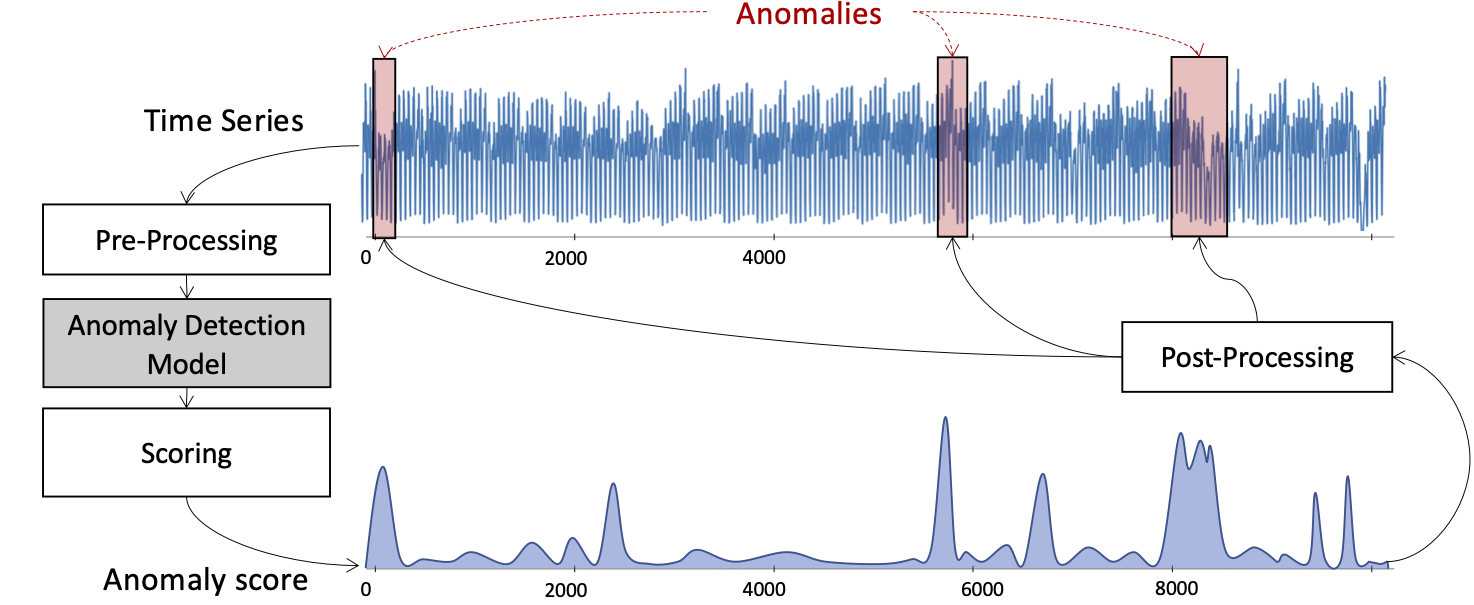
Figure 4: Time series anomaly detection pipeline
The data pre-processing step represents how the anomaly detection method processes the time series data at the initial step. We have noticed all the anomaly detection models are somehow based on a windowed approach initially – converting the time series data into a matrix with rows of sliding window slices of the original time series. The pre-processing step consists of the additional processing procedure besides the window transformation, which varies from statistical feature extraction or any relevant normalization step to perform before.
After the data is processed, different detection methods are implemented, which might be simply calculating distances among the processed subsequences, fitting a classification hyper-plane, or using the processed model to generate new subsequences and comparing them with original subsequences.
Then, during the scoring process, the results derived in the detection methods will be converted to an anomaly score that assesses the abnormality of individual points or subsequences by a real value (such as a probability of being an anomaly). The resulting score is a time series of the same length as the initial time series. In order to guarantee this last condition, some extra steps might be needed (such as padding).
Lastly, during the post-processing step, the anomaly score time series is processed to extract the anomalous points or intervals. Usually, a threshold value will be determined, where the points with anomaly scores surpassing the threshold will be marked as the anomaly. This last step is sometimes ignored by researchers working on time series anomaly detection, but for a good reason: Defining such a threshold is heavily dependent on the use cases. In many applications, only the analyst knowing perfectly the use case can set the optimal threshold.
Anomaly Detection Taxonomy
In the previously described pipeline, the pre-processing and post-processing steps are usually quite generic or on the contrary domain and application dependent. However, the detection methods and the scoring can be solved in many different ways. Despite an enormous amount of methods proposed in the literature from very different communities (data management, data mining, machine learning, etc), we propose here a process-centric taxonomy of the detection methods.
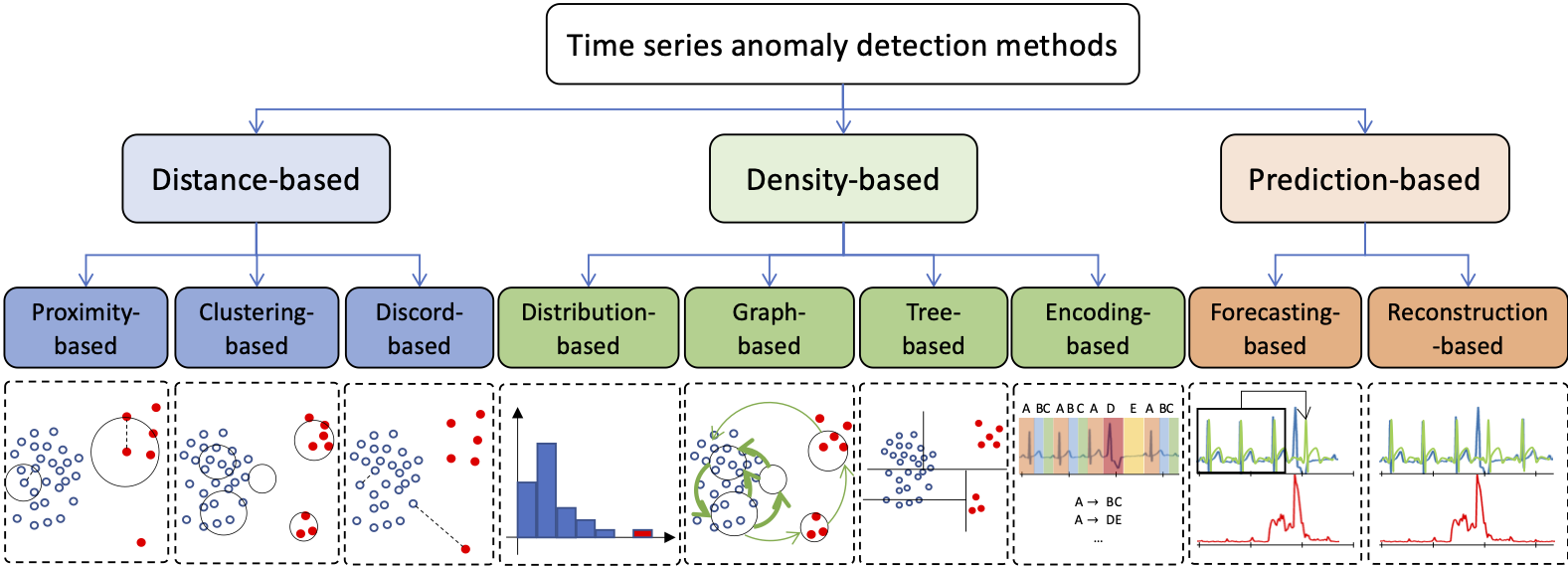
Figure 5: Process-centric Anomaly Detection Taxonomy
We divide methods into three categories: (i) distance-based, (ii) density-based, and (iii) prediction-based. Figure 5 illustrates our proposed process-centric taxonomy. (Note that the second-level categorization is not mutually exclusive; e.g., a model might encode the time series data while adopting a discord-based identification strategy.)
Distance-based contains methods that focus on the analysis of subsequences for the purpose of detecting anomalies in time series, mainly by utilizing distances to a given model. This is done purely from the raw time series, using a variety of time series distance measures. Overall, the distance-based algorithms operate on the original time series as is, without the need for further pre-processing.
Density-based methods focus on detecting globally normal or isolated behaviors. They employ time series representations, and measure density in the space that represents the subsequences of the original time series. These representations can be graphs, trees, histograms, grammar induction rules, and others.
Prediction-based methods train a model to reconstruct the normal data, or predict the future expected normal points. The prediction error is then used to detect abnormal points or subsequences. The underlying assumption of prediction-based methods is that normal data are easier to predict, while anomalies are unexpected, leading to higher prediction errors. Such assumptions are valid when the training set contains no (or almost no) anomalies. Therefore, prediction-based methods are usually more optimal under semi-supervised settings. You may find more detailed information on these methods in [2].
The example of NormA: A distance-based approach
Among all the distance-based approaches proposed in the literature let’s have a closer look at NormA [3]. The latter is a clustering-based algorithm that summarizes the time series with a weighted set of sub-sequences. The normal set (weighted collection of sub-sequences to feature the training dataset) results from a clustering algorithm, and the weights are derived from cluster properties (cardinality, extra-distance clustering, time coverage).
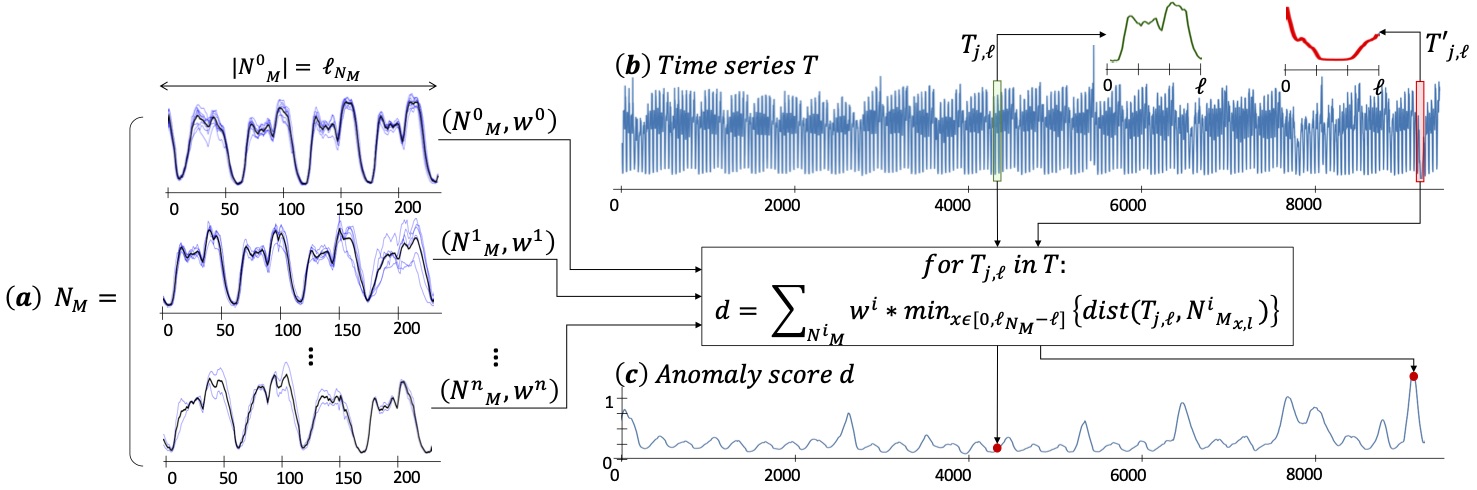
Figure 6: NormA pipeline
Then, for each subsequence of the time series, we compute the average distance to all centroids weighted by the property previously listed. A large weighted distance means that the subsequence is far from all clusters, or belongs to a cluster with a low weight (small cluster, an isolated one or covering only a small time interval of the time series). Thus, a large distance indicates potential anomalies. The anomaly detection process employed by NormA is illustrated in Figure 6. Moreover, An extension of NormA, called SAND [4], has been proposed for streaming time series.
The example of Series2Graph: A density-based approach
As mentioned earlier, density-based approaches employ time series representations to estimate the density or the isolation of points or subsequence. For instance, a possible approach is to convert the time series into a directed graph with nodes representing the usual types of subsequences and edges representing the frequency of the transitions between types of subsequences. Series2Graph [5] is building such kinds of graphs.
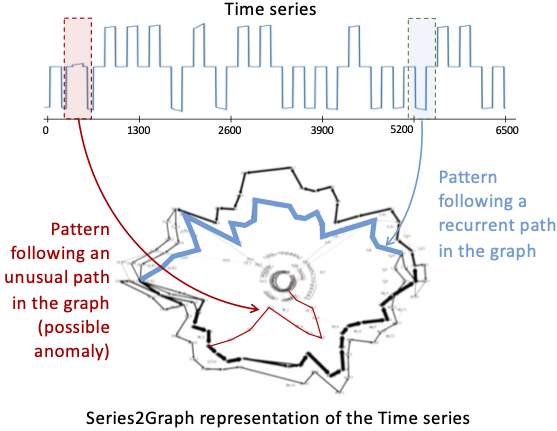
Figure 7: Example of Series2Graph representation
Series2Graph is composed of three steps. The first aims to project all subsequences of the time series into a two-dimensional space, where shape similarity is preserved. Then, a node is created for each one of the densest parts of that space. These nodes can be seen as a summarization of all major patterns of a given length that occurs in the time series. The final step consists of retrieving all transitions between pairs of consecutive subsequences represented by two different nodes. The weights of these edges correspond to the number of transitions that occur between the corresponding two nodes. At the end, we obtain a graph as the one illustrated in Figure 7, and we can use it to detect anomalies. More precisely, we can use the degree of the nodes and the weight of the edges to compute a score. As illustrated in Figure 7, trajectories in the graph (that corresponds to a subsequence in the time series) crossing nodes and edges with low degrees and low weights respectively will be considered as anomalies.
A meta analysis of the literature
It is interesting to highlight the popularity of the different classes of methods over time. Figure 8 shows the number of methods proposed per interval of years (left) and the cumulative number over the years (right). We observe that the number of methods proposed yearly was constant between 1990 and 2016. The number of methods proposed in the literature significantly increased after 2016. This first confirms the growing academic interest in the topic of time-series anomaly detection. We also observe a significant increase in popularity of prediction-based methods, more specifically, by deep learning (i.e., LSTM and autoencoder-based) approaches. Between 2020 and 2023, such methods represent almost 50% of the newly introduced anomaly detection methods. Despite the hype, though, these methods do not offer any significant advantage over the other methods.
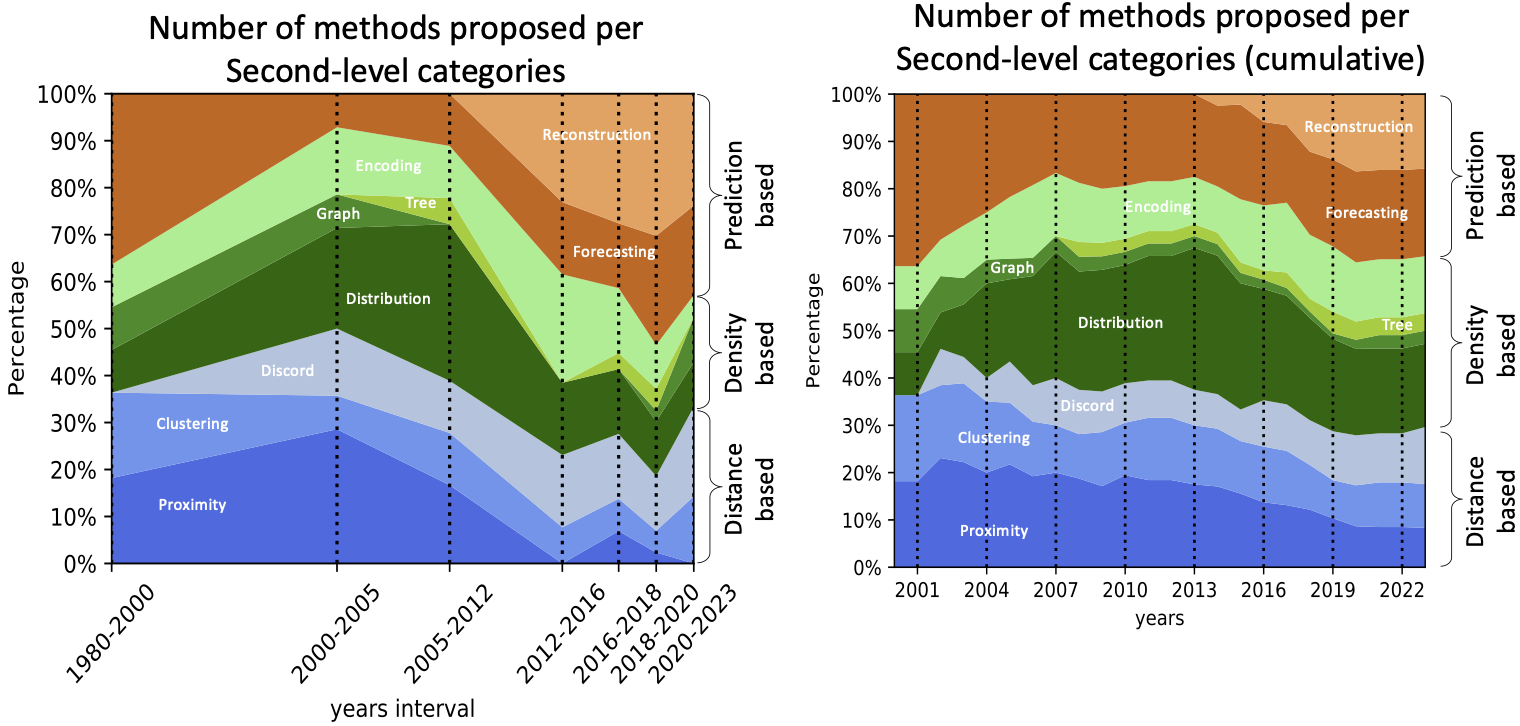
Figure 8: Relative number of methods proposed over time per category, at different times-intervals (left), and cumulative (right).
Evaluating the Anomaly Detection Quality: a Tricky Challenge
With the continuous advancement of time-series anomaly detection methods, it becomes evident that different methods possess distinct properties and may be more suitable for specific domains. Moreover, the metrics used to evaluate these methods vary significantly in terms of their characteristics. Consequently, evaluating and selecting the most appropriate method for a given scenario has emerged as a major challenge in this field. The challenges are two-fold: (i) Which is the most appropriate dataset of time series to compare anomaly detection methods? (ii) How can we assess the performance of anomaly detection methods on detecting real anomalies?
Which is the most appropriate dataset of time series to compare anomaly detection methods?
Multiple surveys and experimental studies have evaluated the performance of various anomaly detectors across different datasets [6,7]. These investigations have consistently highlighted the absence of a one-size-fits-all anomaly detector.
Consequently, there have been efforts to establish benchmarks incorporating multiple datasets from various domains to ensure a thorough and comprehensive evaluation. The main benchmarks proposed in the literature are the following:
- NAB [8] provides 58 labeled real-world and artificial time series, primarily focusing on real-time anomaly detection for streaming data. It comprises diverse domains such as AWS server metrics, online advertisement clicking rates, real-time traffic data, and a collection of Twitter mentions of large publicly-traded companies.
- Yahoo [9] comprises a collection of real and synthetic time series datasets, which are derived from the real production traffic to some of the Yahoo production systems.
- Exathlon [10] is proposed for explainable anomaly detection over high-dimensional time series data. It is constructed based on real data traces from repeated executions of large-scale stream processing jobs on an Apache Spark cluster.
- KDD21 [11] is a composite dataset that covers various domains, such as medicine, sports, and space science. It contains mostly synthetic anomalies that were designed to address the pitfalls of previous benchmarks.
- TODS [12] refines synthetic criterion and includes five anomaly scenarios categorized by behavior-driven taxonomy as point-global, pattern-contextual, pattern-shapelet, pattern-seasonal, and pattern-trend.
- TSB-UAD [6] is a comprehensive and unified benchmark that includes public datasets with real-world anomalies, as well as synthetic datasets that provide eleven transformation methods to emulate different anomaly types.
We note that different studies have discussed the flaws of some of the datasets used in these benchmarks [13,6,7]. Overall, we observe that designing and agreeing on a comprehensive benchmark is an open question that the community needs to address.
How can we assess the performance of anomaly detection methods on detecting real anomalies?
This question is not as straightforward as it seems. At a first glance, anomaly detection should be evaluated with regular accuracy measures used in other domains, such as Precision, Recall and F score. However, such measures require a threshold to be set. Such thresholds (as discussed in the generic pipeline of this blogpost) are difficult to be set and heavily depend on the domain and the expert knowledge. Setting a threshold on an unsupervised manner is possible (usually set to three times the standard deviation of the anomaly score), but might be unfair for some methods. To tackle this issue, we can use threshold independent measures (such as Area-Under-the-Curve measures as AUC-ROC or AUC-PR). Nevertheless, one major problem specifically related to time series still remains: The inconsistent labeling tradition across datasets, combined with the anomaly scores misalignment with labels caused by mechanism differences between anomaly detection methods, lead to serious difficulties to compare anomaly detection methods altogether with the previously mentioned measures.
If you cannot fix the labels, change the measure: Range-based and VUS-based
As we have seen previously, classical threshold-based and AUC-based are primarily designed for point-based anomalies, treating each point independently and assigning equal weight to the detection of each point in calculating the overall AUC. We have also seen that these metrics may not be ideal for assessing subsequence anomalies due to labeling misalignment with the anomaly score. To address these limitations, an extension of the ROC and PR curves called Range-AUC has been introduced specifically for subsequences. By adding a buffer region at the outliers’ boundaries, it accounts for the false tolerance of labeling in the ground truth and assigns higher anomaly scores near the outlier boundaries. It replaces binary labels with continuous values between 0 and 1.
Nevertheless, the buffer length in Range-AUC needs to be predefined. If not properly set, it can strongly influence range-AUC measures. To eliminate this influence, VUS (Volume Under the Surface) [14] computes Range-AUC for different buffer lengths from 0 to a user-defined upper bound, which leads to the creation of a three-dimensional surface in the ROC or PR space. As a consequence, the VUS family of measures, including VUS-ROC and VUS-PR, are essentially parameter-free and threshold-independent.
A Step Forward: Ensembling and Model Selection
We note that the most recent benchmarks and experimental evaluations have led to the same conclusion: no method exists that outperforms all the others on all time series from various domains. The following two reasons explain this large difference in performance among datasets: (i) heterogeneity in anomaly types; and (ii) heterogeneity in time series structures. In practice, we observe that some methods outperform others on specific time series with either specific characteristics (e.g., stationary or non-stationary time series) or anomalies (e.g., point-based or sequence-based anomalies).
To overcome the above limitation, ensembling solutions have been proposed that consist of running all existing anomaly detection methods and averaging all anomaly scores. Nevertheless, such solutions require running all methods, resulting in an excessive cost that is not feasible in practice.
Therefore, a scalable and viable solution to solve anomaly detection over very different time series is a model selection method that will select, based on time series characteristics, the best anomaly detection method to run. This topic has been tackled in several recent research works related to AutoML (Automated Machine Learning) for the general case of anomaly detection.
Ιn this direction, a recent study proposed the Model Selection for Anomaly Detection (MSAD) framework [15]. MSAD evaluated the performance of time series classification methods used as model selection for anomaly detection in time series, and proposed a pipeline that enables any kind of time series classifier to be used for any univariate time series with different lengths.
Overall, MSAD compared 16 different classifiers over 1980 time series and 12 anomaly detection methods from the recent anomaly detection benchmark TSB-UAD [6]. The results demonstrate that model selection methods outperform every single anomaly detection method, while maintaining the same order of magnitude cost in terms of execution time. Figure 11 shows a summary of the experimental evaluation, where the best model selection method (in blue in Figure 11) is up to 2.8 times more accurate than the best anomaly detection method in the TSB-UAD benchmark and 1.9 times more accurate than the Average Ensembling solution.
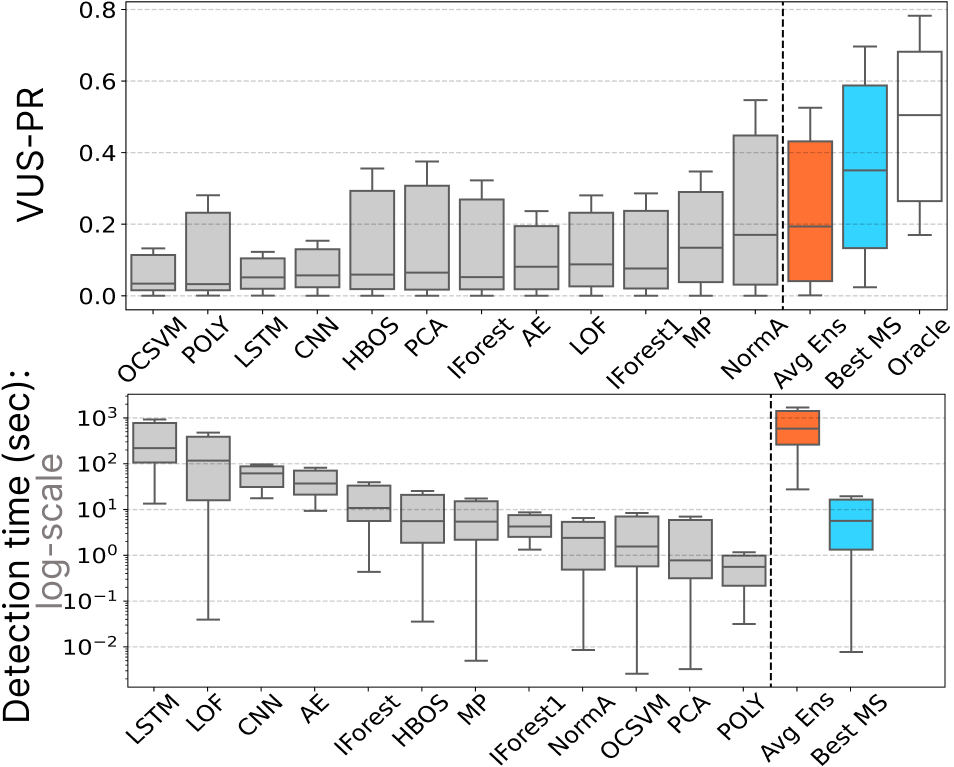
Figure 11: Summary of our evaluation on the TSB-UAD benchmark of model selection methods (best in blue) when compared to 12 anomaly detection methods and the Average Ensembling (in orange).
This evaluation is the first step to demonstrate the accuracy and efficiency of time series classification algorithms for anomaly detection. It represents a strong baseline that can then be used to guide the choice of approaches for the model selection step in more general AutoML pipelines. Nevertheless, we also observed that such model selection methods are still not appropriate for “out-of-distribution” scenarios (i.e., training on a specific type of time series while testing on a completely different one). As a matter of fact, more research toward that direction is still needed to demonstrate the practical benefit of model selection for time series anomaly detection.
Bloggers Profiles

Paul Boniol is a researcher at Inria, member of the VALDA project-team which is a joint team between Inria Paris, École Normale Supérieure, and CNRS. Previously, he worked at ENS Paris-Saclay (Centre Borelli), Université Paris Cité, EDF Research lab, and Ecole Polytechnique (LIX). His research interests lie between data analytics, machine learning, and time-series analysis. His Ph.D. dissertation focused on subsequence anomaly detection and time-series classification, and won PhD awards, including the prestigious Paul Caseau Prize, supported by the Academy of Sciences of France. His work has been published in the top data management and data mining venues.

Themis Palpanas is an elected Senior Member of the French University Institute (IUF), a distinction that recognizes excellence across all academic disciplines, and Distinguished Professor of computer science at the University Paris Cite (France), where he is director of the Data Intelligence Institute of Paris (diiP), and director of the data management group, diNo. He received the BS degree from the National Technical University of Athens, Greece, and the MSc and PhD degrees from the University of Toronto, Canada. He has previously held positions at the University of California at Riverside, University of Trento, and at IBM T.J. Watson Research Center, and visited Microsoft Research, and the IBM Almaden Research Center. His interests include problems related to data science (big data analytics and machine learning applications). He is the author of 14 patents. He is the recipient of 3 Best Paper awards, and the IBM Shared University Research (SUR) Award. His service includes the VLDB Endowment Board of Trustees (2018-2023), Editor-in-Chief for PVLDB Journal (2024-2025) and BDR Journal (2016-2021), PC Chair for IEEE BigData 2023 and ICDE 2023 Industry and Applications Track, General Chair for VLDB 2013, Associate Editor for the TKDE Journal (2014-2020), and Research PC Vice Chair for ICDE 2020.
References
[1] Themis Palpanas, Volker Beckmann. Report on the First and Second Interdisciplinary Time Series [a.k.a. data series, or sequences] Analysis Workshop (ITISA). ACM SIGMOD Record 48(3), 2019.
[2] Paul Boniol, John Paparrizos, Themis Palpanas. New Trends in Time Series Anomaly Detection. International Conference on Extending Database Technology (EDBT), Ioannina, Greece, March 2023. (video)
[3] Paul Boniol, Michele Linardi, Federico Roncallo, Themis Palpanas, Mohammed Meftah. Emmanuel Remy. Unsupervised and Scalable Subsequence Anomaly Detection in Large Data Series. International Journal on Very Large Data Bases (VLDBJ), 2021.
[4] Paul Boniol, John Paparrizos, Themis Palpanas, Michael J. Franklin. SAND: Streaming Subsequence Anomaly Detection. Proceedings of the VLDB Endowment (PVLDB) Journal, 2021.
[5] Paul Boniol, Themis Palpanas. Series2Graph: Graph-based Subsequence Anomaly Detection for Time Series. Proceedings of the VLDB Endowment (PVLDB) Journal 13(11), 2020.
[6] John Paparrizos, Yuhao Kang, Ruey Tsay, Paul Boniol, Themis Palpanas, Michael J. Franklin. TSB-UAD: An End-to-End Benchmark Suite for Univariate Time-Series Anomaly Detection. Proceedings of the VLDB Endowment (PVLDB) Journal, 2022.
[7] Sebastian Schmidl, Phillip Wenig, and Thorsten Papenbrock. 2022. Anomaly detection in time series: a comprehensive evaluation. Proceedings of the VLDB Endowment (PVLDB) Journal, 2022.
[8] Subutai Ahmad, Alexander Lavin, Scott Purdy, Zuha Agha: Unsupervised real-time anomaly detection for streaming data, Neurocomputing, Volume 262, 2017.
[9] Nikolay Laptev, Saeed Amizadeh, Youssef Billawala: S5 a labeled anomaly detection dataset, v1.0 (16M), 2015
[10] Vincent Jacob, Fei Song, Arnaud Stiegler, Bijan Rad, Yanlei Diao, and Nesime Tatbul. Exathlon: a benchmark for explainable anomaly detection over time series. Proceedings of the VLDB Endowment (PVLDB) Journal, 2021.
[11] Eamonn J. Keogh, Taposh Dutta Roy, U. Naik, and A Agrawal. Multi-dataset Time-Series Anomaly Detection Competition 2021. 2021.
[12] Kwei-Herng Lai, Daochen Zha, Junjie Xu, Yue Zhao, Guanchu Wang, Xia Hu. Revisiting time series outlier detection: Definitions and benchmarks. NeurIPS, 2021
[13] Wu Renjie, Eamonn J. Keogh. Current Time Series Anomaly Detection Benchmarks are Flawed and are Creating the Illusion of Progress. IEEE Transactions on Knowledge and Data Engineering 35 (2020): 2421-2429.
[14] John Paparrizos, Paul Boniol, Themis Palpanas, Ruey S. Tsay, Aaron Elmore, Michael J. Franklin. Volume Under the Surface: A New Accuracy Evaluation Measure for Time-Series Anomaly Detection. Proceedings of the VLDB Endowment (PVLDB) Journal, 2022.
[15] Emmanouil Sylligardos, Paul Boniol, John Paparrizos, Panos Trahanias, Themis Palpanas. Choose Wisely: An Extensive Evaluation of Model Selection for Anomaly Detection in Time Series. Proceedings of the VLDB Endowment (PVLDB) Journal, 2023.