To KG or not to KG, that is the question!
Even before retrieval augment generation (RAG) became a buzzword, researchers have been working on the infusion of knowledge bases with language models, allowing for better nudging of parametric knowledge in these models [1]. The source of this external knowledge can range from subject-relation-object tuples from knowledge graphs (KG) to summaries of Wikipedia pages. While studies have reported improved performance on standard benchmarks, there are two shortcomings. Firstly, determining the exact causal relation and impact of knowledge token infusion is challenging to track. Secondly, the efficacy of knowledge-infused language models for subjective tasks has not been well studied. One downstream task where external and explicit knowledge has been hypothesised to help is in a better understanding of implicit language like memes [5], sarcasm [6] and hate speech [2]. Work attempting to incorporate knowledge tuples from ConceptNet (a large-scale general-purpose knowledge graph) observed that early fusion of knowledge tuples is better than late fusion [2]. Yet, across implicit hate speech datasets, KG tuples do not provide a consistent improvement on both automated and human evaluation metrics [2,3]. As the literature on knowledge infusion only reports performance for the inclusion of the top-k entities, we do not have a clear picture of what happens if the top-k entities are corrupted. In other words, “if top-k tuples are responsible for performance improvements, then replacing top-k with bottom-k or a random-k set should lead to proportional loss in performance.”
Setup: Using the task of implicit hate explanation, where, for a given implicit hate speech, the aim is to generate a short text explaining the implied context matching the manual/golden explanation, we test the above hypothesis.
We incorporated two implicit hate explanation datasets of varying sizes, and two KGs of different specificity (one general purpose and one task-oriented). We finetuned variants of the BART-base language model to observe changes in knowledge infusion at the input stage (i.e concatenation of knowledge tuples with input hate speech). The change was recorded in terms of natural language generation (NLG) performance metrics, which are the de facto standard for reporting on any generative task. In total, for a given dataset, we obtained four finetuned models per KG. k=20 is adopted from existing literature in hate explanation [2].
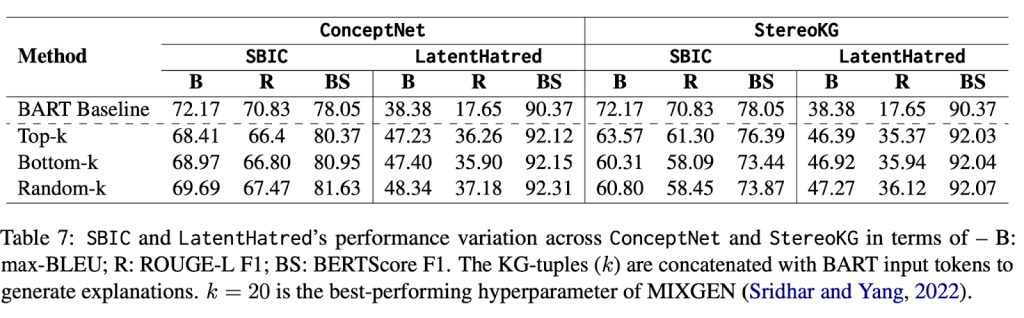
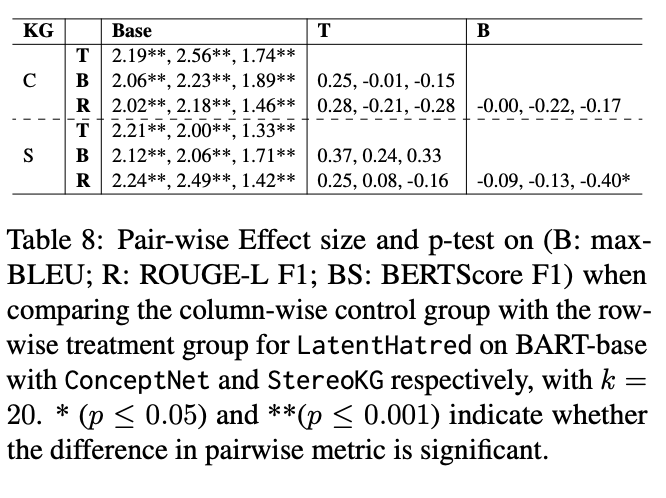
Initial observations: Overall, we observed that compared with the base case (no external knowledge infusion), the addition of top-k KG tuples led to a performance increase in one dataset and degradation in another (Table 7). More interesting was the fact that comparing top-k, bottom-k, and random-k in any of the datasets+KG setups did not display any visible degradation in performance. Significance testing with the dataset that initially benefited from top-k further indicated that, by chance, replacing top-k tuples with random-k or bottom-k will not significantly alter the metric-level performance (Table 8).
Manual inspection: To ascertain the low quality of KG tuples, we manually inspected randomly selected 20 samples from each dataset+KG pair. We clearly observed that the top-k tuples showcased that very few contain task-specific, i.e., very few were successful in conveying a hateful connotation. Since the standard process of TF-IDF or cosine similarity-based query-KG matching, as well as ranking, is task agnostic in general, the tuples so obtained are also task agnostic and less diverse. The low diversity of tuples was also quantified by observing the distribution of relevance scores (employed to rank the tuples for the top-k filter) for the dataset+KG pair.
For detailed results, we encourage readers to check out Section 5 of our paper [3].
Some potential solutions: Some clear takeaways emerging from our endeavour are:
- Generic retrieval techniques, while scalable, come at the cost of task-specific performance. Whether the task-specific approach is to be introduced in the querying step or the ranking step remains an open question. Both come with their pros and cons. I postulate that performing better filtering at the query level would be more effective (trickle-down effect). For example, for toxicity explanation, if we can determine which spans of text are indicators of the vulnerable group being targeted, then those spans can receive a higher weightage when the query vector is generated.
- Secondly, the evaluation of knowledge infusion, especially KG-tuples, needs to accommodate task-specific metrics. For example, in our task, the assessment can be the increase in explicit toxicity when the implied explanations are KG-infused vs not [3]. Such metrics can also be used as a reward for the loss function during finetuning.
- Lastly, our experiment reveals that human evaluations are critical even if done on a small scale. Employing LLMs-as-judge to augment human evaluations at scale can be one way forward.
Open questions for the research community:
In addition to our potential solutions, there remain some broad, open questions for knowledge infusion:
- Firstly, for heterogeneous knowledge graphs, how can we better incorporate the topology (non-sequential structure) in seq-2-seq models?
- Our experiments were run on BART, but at what size of language models, especially for large language models (LLMs), does RAG-based knowledge infusion become ineffective? [4]
- Our work [3] and previous work [2] in toxicity explanations have found that infusing external context works better at the input level compared to late fusion. However, in the case of explaining memes, late fusion seems to work better [7]. How different NLP tasks behave w.r.t fusion techniques is an interesting question that can help reduce the search space of experiments to run w.r.t knowledge infusion.
- For knowledge graphs, how can we better incorporate multi-hop connections? Moreover, at what hop should the retrieval stop? Can some task-specific thresholding be employed?
References:
- Sharma. Retrieval-Augmented Generation: A Comprehensive Survey of Architectures, Enhancements, and Robustness Frontiers. In arxiv. 2025.
- Shridhar & Yang. Explaining Toxic Text via Knowledge Enhanced Text Generation. In NAACL. 2022.
- Masud, et al. Tox-BART: Leveraging Toxicity Attributes for Explanation Generation of Implicit Hate Speech. In ACL Findings. 2024.
- Fayyaz, et al. Collapse of Dense Retrievers: Short, Early, and Literal Biases Outranking Factual Evidence. In ACL. 2025.
- Shivam, et al. MEMEX: Detecting Explanatory Evidence for Memes via Knowledge-Enriched Contextualization. In ACL. 2023.
- Shivani, et al. When did you become so smart, oh wise one?! Sarcasm Explanation in Multi-modal Multi-party Dialogues. In ACL. 2022.
- Abdullakutty & Naseem. Decoding Memes: A Comprehensive Analysis of Late and Early Fusion Models for Explainable Meme Analysis. In WWW Companion Proceedings. 2024.

Author Bio: Sarah Masud is currently a postdoc at the University of Copenhagen, exploring stereotypes and narratives. During her PhD from Indraprastha Institute of Information Technology, New Delhi, she explored the role of different context cues in improving computational hate speech-related tasks. One such work led her to study how knowledge graph tuples impact the generation of toxicity-explaining text. More about her work can be found here: https://sara-02.github.io/